I build ML, RecSys, and LLM systems that serve customers at scale, and write about what I learn along the way. Join 7,500+ subscribers!
How to Write Data Labeling/Annotation Guidelines
Hey friends,
This week's newsletter a day late because I was reeling from the crazy LLM releases yesterday. There was GPT-4, PaLM API, Claude API, and then some. If AI progress from 2020 - 2022 was drinking from a firehose, 2023 is five firehoses.
Today's sharing goes back to the fundamentals in machine learning—collecting ground truth. I don't often have to deliberately collect gound truth, but the few times I do, it's been a challenge. Thus, here are some notes that I hope future me will find useful.
I appreciate you receiving this, but if you want to stop, simply unsubscribe.
• • •
👉 Read in browser for best experience (web version has extras & images) 👈
Writing data labeling/annotation guidelines is hard. For the handful of times I’ve had to do it, I didn’t know where to start or how to improve. You would think that we’re just writing instructions for a task but nooo, turns out there’s a lot more thinking involved.
I know future me will have to write annotation guidelines again. Thus, present me would like to share a few things he’s learned. I’ll frame it around questions that I think a good guideline should answer (the principles of Why, What, How are applicable). We’ll also see examples from guidelines by Google and Bing Search. Addressing these questions should help us write good guidelines that ensure consistent and accurate data labels.
- Why is the task important?
- What is the task?
- What do the terms in the task mean?
- How should annotators decide?
- How should the task be performed?
Why is the task important?
A good guideline should explain why the task is important. This will motivate annotators to put in the effort it deserves. Whether the task is labeling images, annotating sentiment in text, or rating search relevance, tell them why it matters. Explain how the task’s outputs will be used to improve your product or machine learning models. Include screenshots of the UX and explain how the task helps power it.
The examples below are from the first pages of Google’s and Bing’s guidelines. They explain the task and how its output will be used to improve search results.
 |
Google's explanation on the Why
 |
Bing's explanation on the Why
What is the task?
Next, explain the task so annotators understand exactly what they need to do. This may involve helping annotators put themselves in the shoes of users, and possibly breaking the task into smaller pieces.
Google’s guide has an entire section devoted to understanding the needs of a user. It discusses how people use search to perform simple and complex tasks, as well as the various user intents.
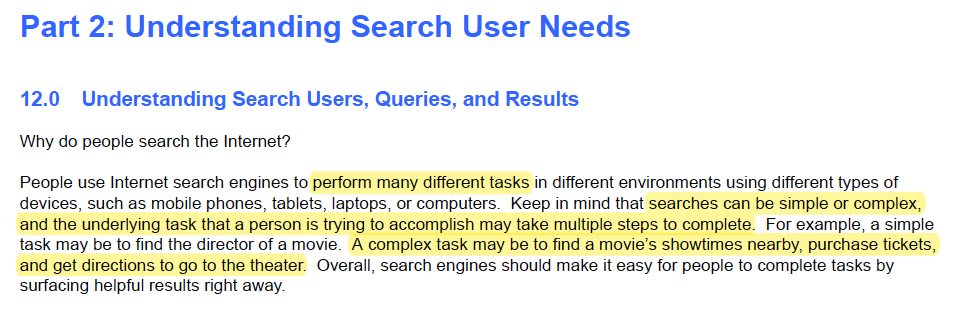 |
Though it may be obvious, it's helpful to spell out the needs of a search user
 |
People using search have various intents such as to know, do, find a website, or visit in person
Both guidelines also explain the labeling options early in the respective sections.
 |
Explaining the labeling options for page quality
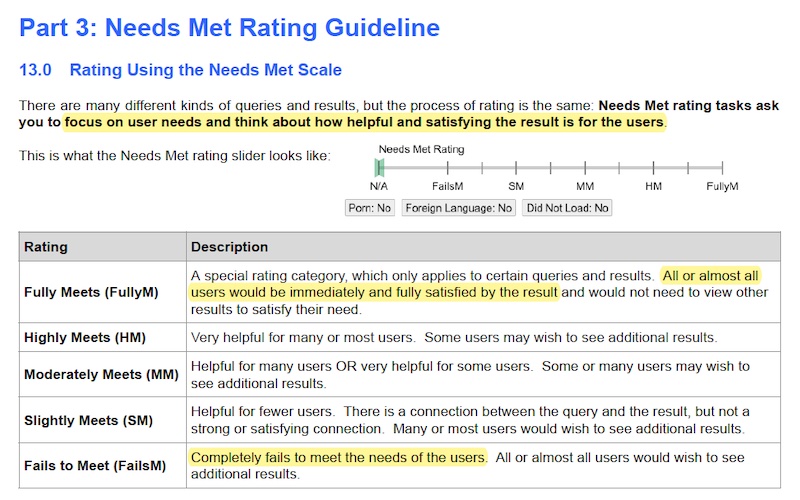 |
Explaining the labeling options for needs met
 |
Explaining the labeling options for location quality
What do the terms in the task mean?
A good guideline should have clear definitions of the terms used. One key challenge when writing annotation guidelines is ensuring that everyone is using the same terminology. This is especially important in technical fields with domain-specific vocabulary, or when developing new user experiences and coining new terms. This goes a long way towards improving the consistency and accuracy of labeled data.
For the seemingly basic task of rating search relevance, Google’s guidelines includes definitions for “query”, “locale”, and even “results”.
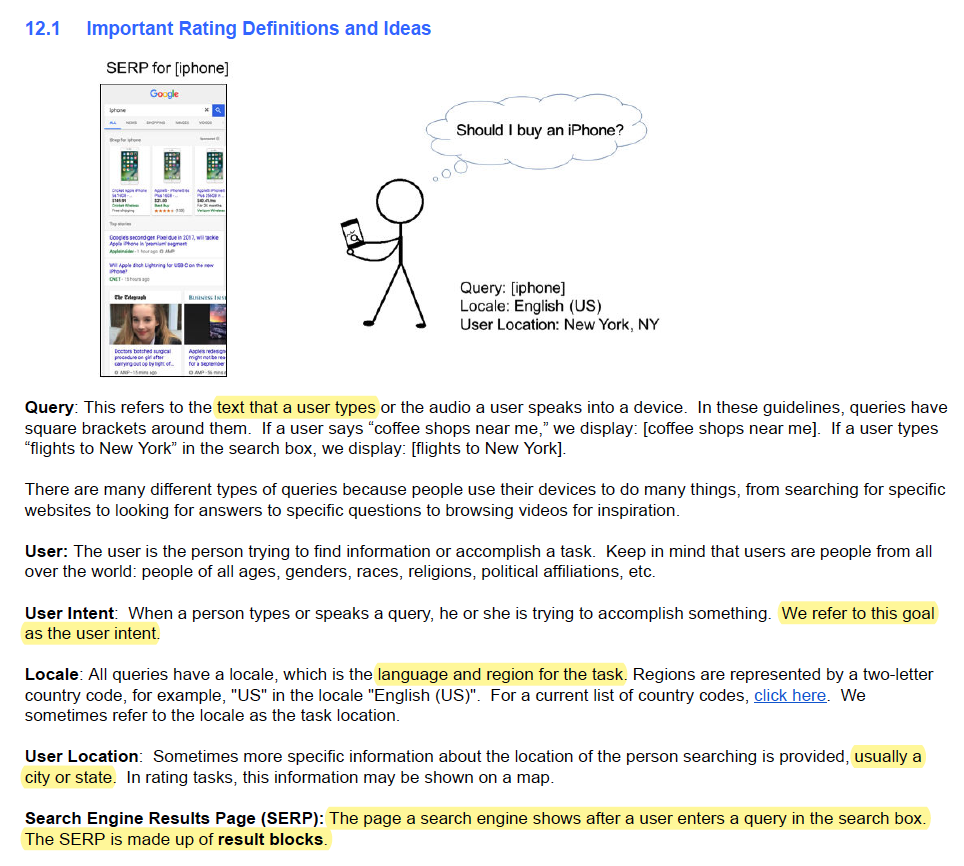 |
 |
Defining the various terms that show up in a search relevance task
Similarly, Bing defines the fields that show up in Bing search results.
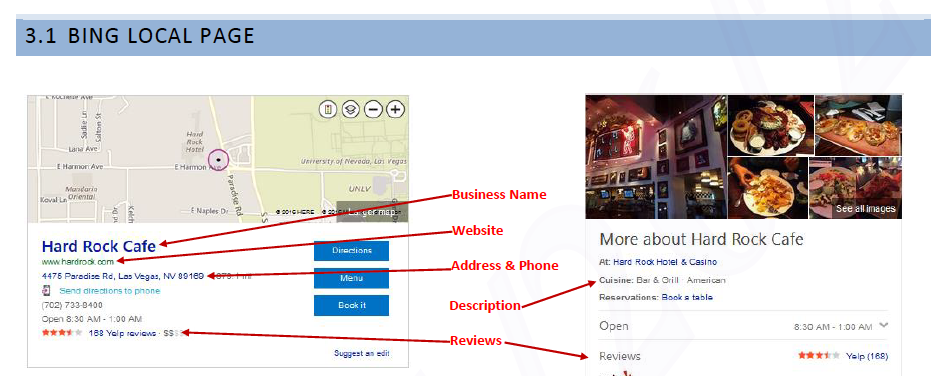 |
Defining the various fields in a Bing local page
How should annotators decide?
Here’s the meat of the guidelines: Explaining how to decide on the labels. It may include broader considerations and context around the task, step-by-step instructions, and challenging examples and explanations.
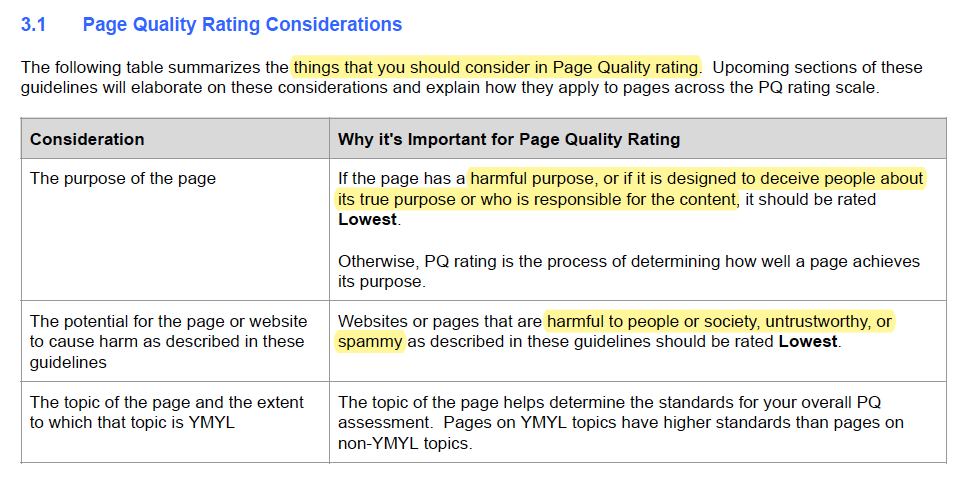
As part of their guidelines on rating page quality, Google includes several aspects of a page that a reviewer should consider, such as page purpose, website type and reputation, and ads on the page.
 |
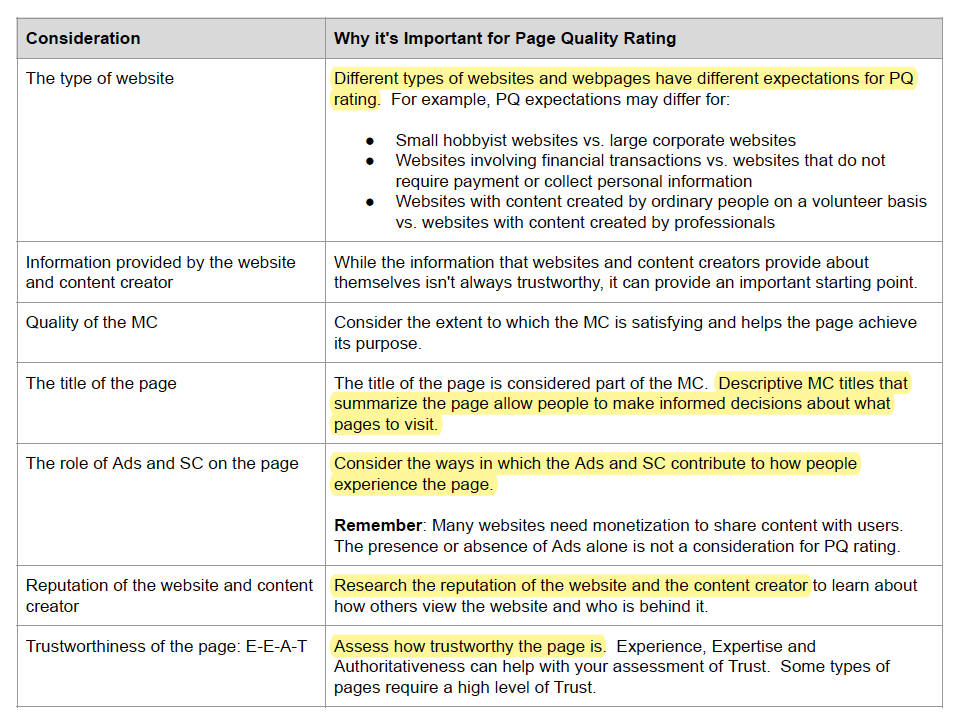 |
Various factors to consider when defining page quality
To help annotators understand what they’re rating (i.e., search queries), Google includes several examples of queries and their intents. They also distinguish between “know”, “do”, and “website” queries.
 |
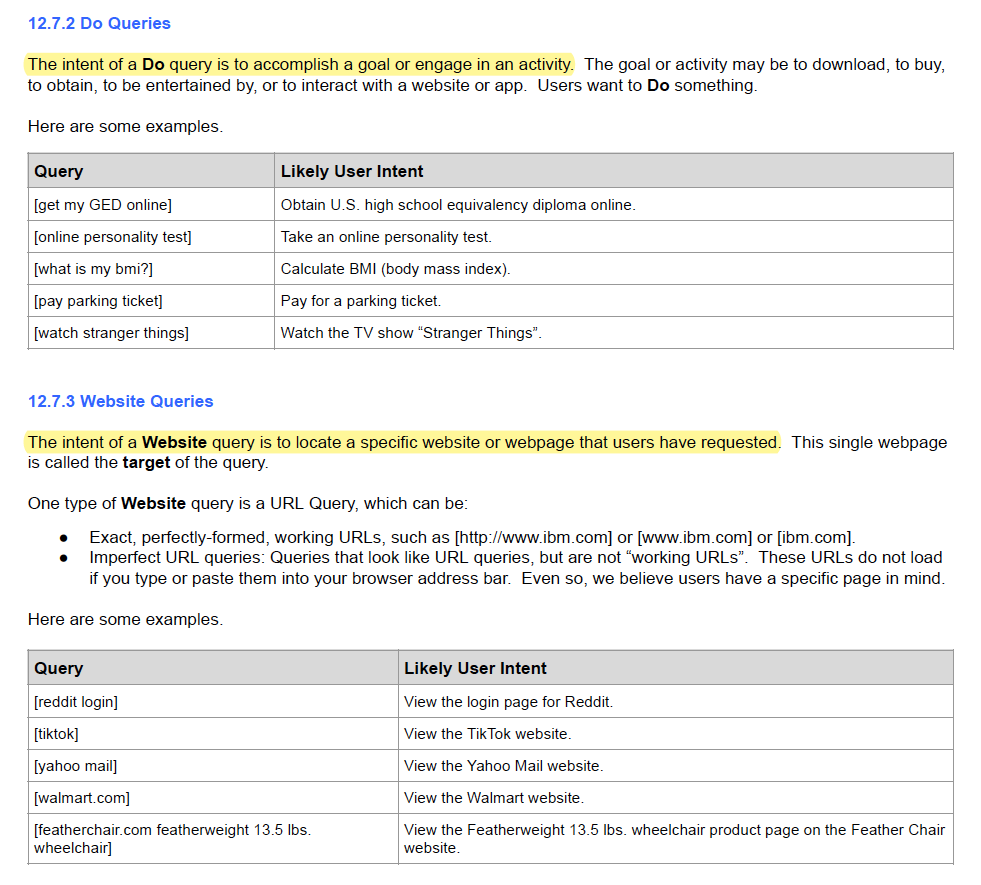 |
Explain the various types of queries a user could make
Bing includes a decision tree for rating match quality, and a step-by-step for rating location quality. Having annotators follow the same decision-making process can lead to more consistent and accurate results, and higher inter-rater agreement.
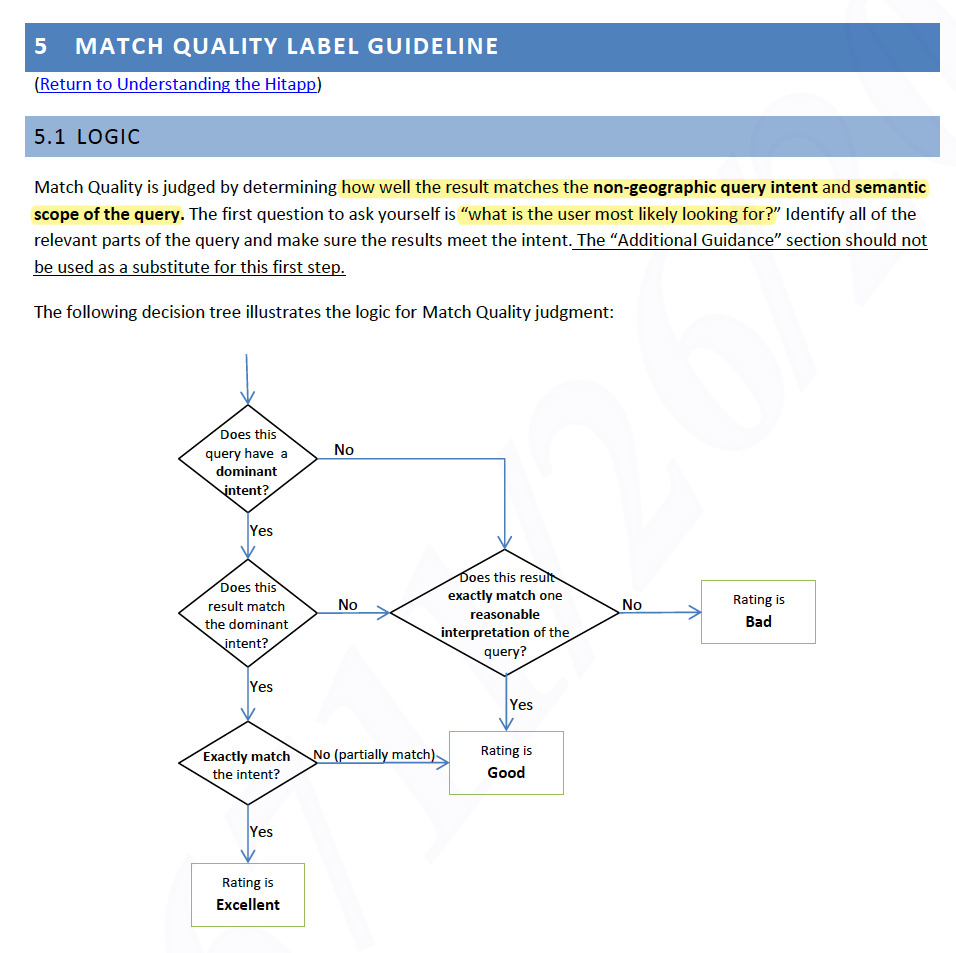 |
A decision tree to assess match quality based on query intent and semantic scope
 |
A step-by-step to rate location quality given a query intent
To help annotators decide better and increase precision, we can provide examples of tasks with their associated output and explanations. This helps to calibrate annotators so we get higher inter-rater reliability. Google’s guidelines have a ton of these examples.
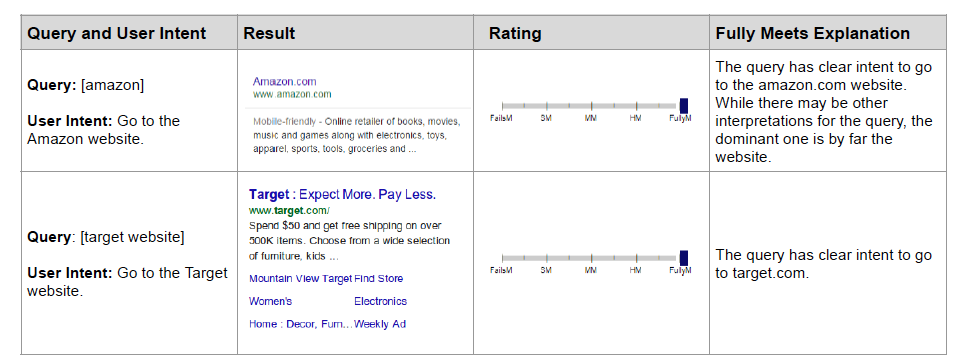 |
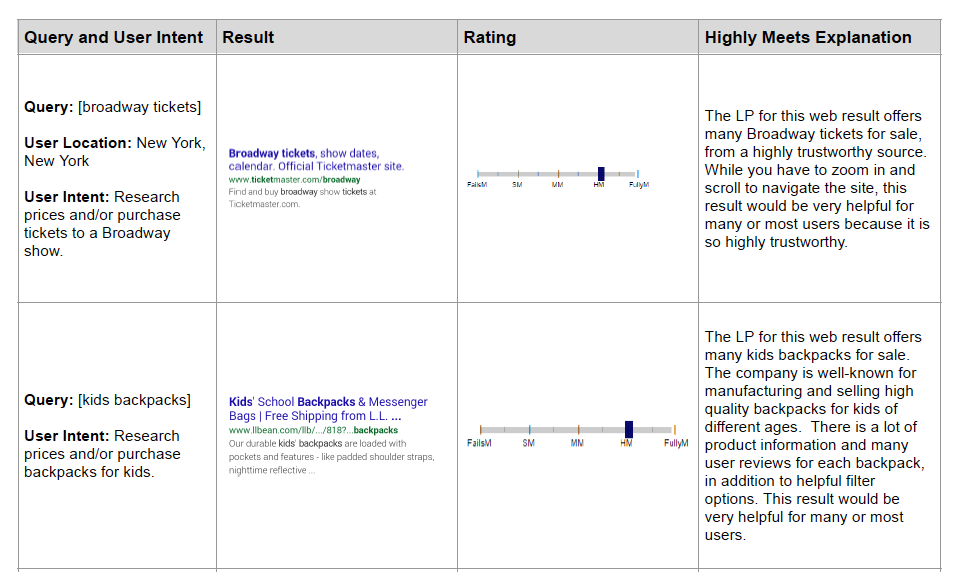 |
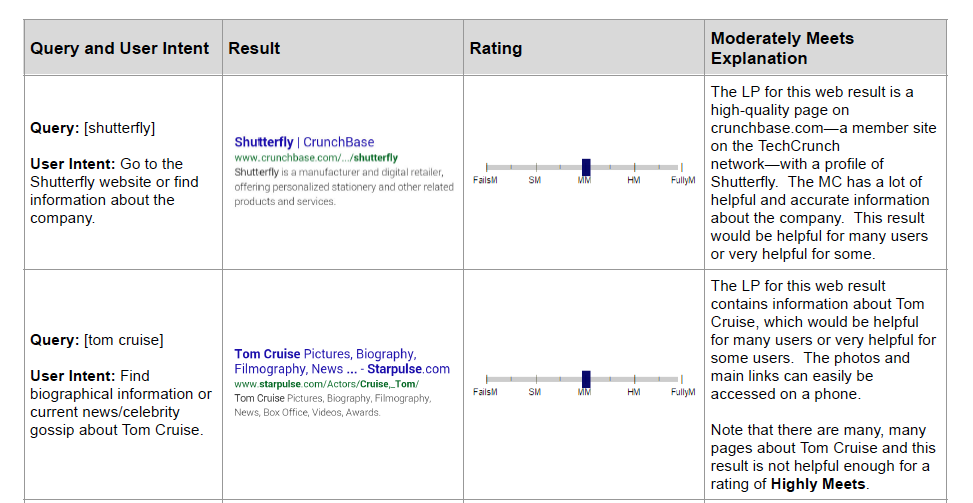 |
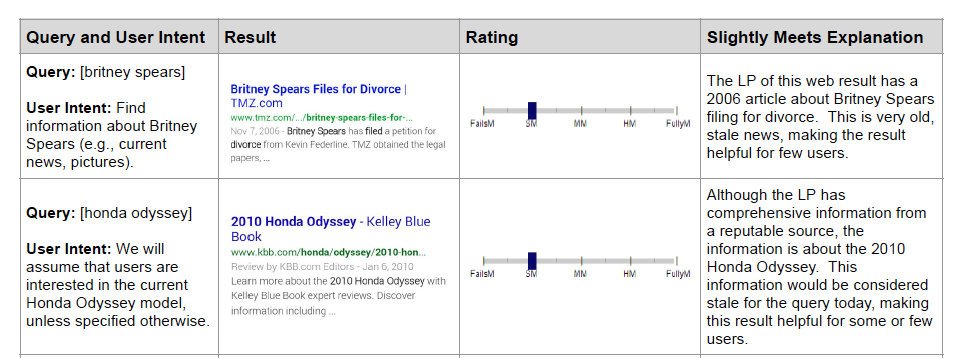 |
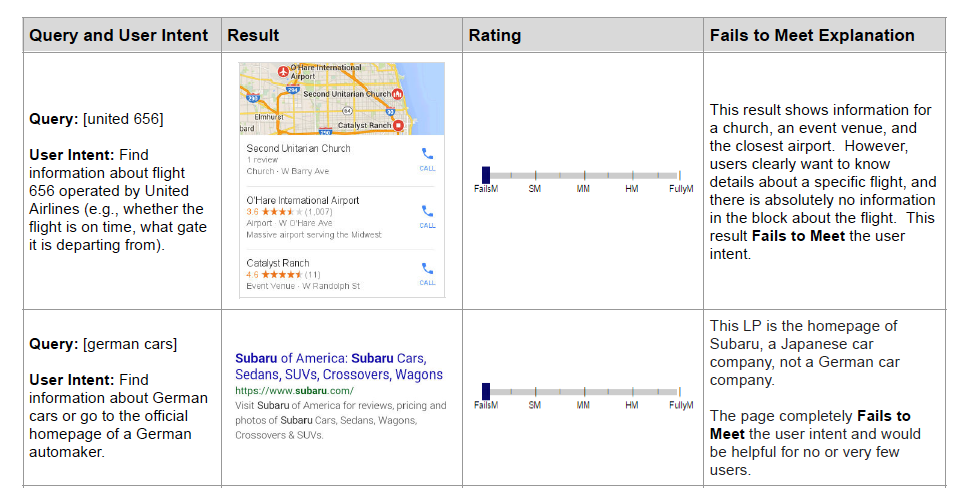 |
Various needs met ratings and their explanations
How should the task be performed?
Don’t forget to include instructions on how to access and use the annotation tools and platforms, as well as the logistics of the task.
For example, the guide for page quality rating asks annotators not to spend too much time on each rating, how to decide between two ratings, and how to decide when the criteria doesn’t cover it (they should use their judgment).
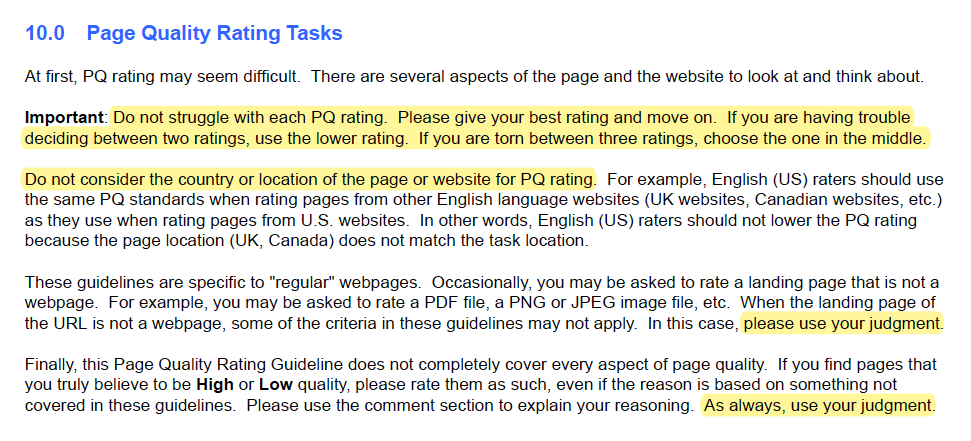 |
How much time to spend on each task and how to break ties
It’s also important to clarify what annotators should do if they can’t perform the task. Rather than forcing them to make a possibly incorrect judgment, we can provide an “Unsure” label or let them release the task.
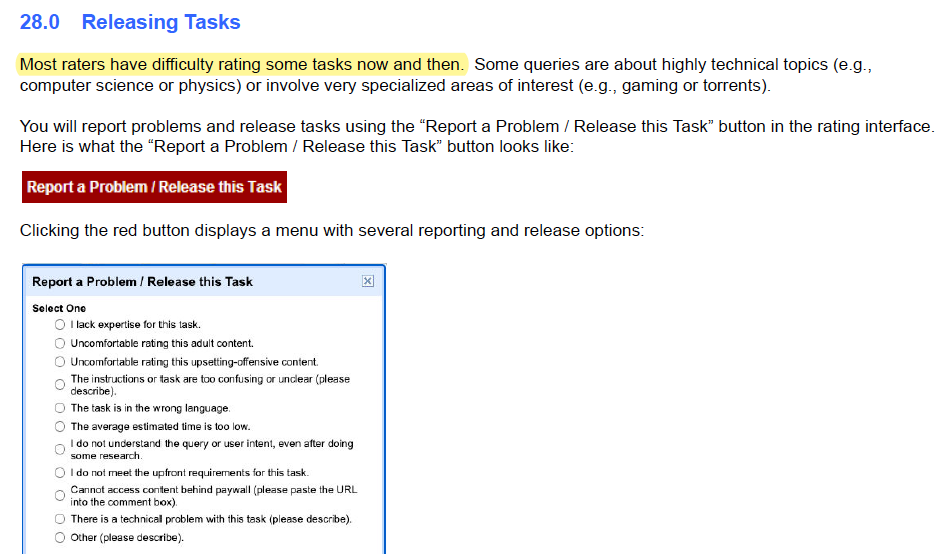 |
What annotators should do if they have difficulty with a task
• • •
Improving the quality of labels collected is not only about writing good labeling guidelines. We can also simplify the task to use binary responses instead of a numeric scale or multiple choice options. This can increase precision and throughput.
In addition, try to make labeling criteria as objective as possible. For example, “Is this adult content?” can be made more objective by rephrasing it as “Is this nudity?” Nonetheless, it’s okay if the task is somewhat subjective—that’s why we have human reviewers. As a comparison, Google’s guidelines ask annotators to “use your judgment” 19 times!
To evaluate your task and labeling guidelines, consider measuring how often reviewers agree with each other (i.e., inter-rater reliability). Cohen’s kappa is a commonly used metric. If Cohen’s kappa stays consistent or increases as you iterate on your task definition and labeling guidelines, you’re on the right track.
Eugene Yan
I build ML, RecSys, and LLM systems that serve customers at scale, and write about what I learn along the way. Join 7,500+ subscribers!
Hey friends, Recently, I've been wondering if I should migrate from my current web app stack (FastAPI, HTML, CSS, and some JavaScript) towards a modern web framework. I was particularly interested in FastHTML, Next.js, and Svelte. To learn more about these frameworks, I built the same web app using each of them. Here's what I learned, plus some thoughts on how coding assistances can and will influence developer habits and choices. I appreciate you receiving this, but if you want to stop,...
Hey friends, I've been thinking and experimenting a lot with how to apply, evaluate, and operate LLM-evaluators and have gone down the rabbit hole on papers and results. Here's a writeup on what I've learned, as well as my intuition on it. It's a very long piece (49 min read) and so I'm only sending you the intro section. It'll be easier to read the full thing on my site. I appreciate you receiving this, but if you want to stop, simply unsubscribe. 👉 Read in browser for best experience (web...
Hey friends, Just got back from the AI Engineer World's Fair and it was a blast! I had the opportunity to give the closing keynote, as well as host GitHub CEO Thomas Dohmke for a fireside chat. Along the same lines, I've been thinking about how to interview for ML/AI engineers and scientists, and got together with Jason to write about the technical and non-technical skills to look for, how to phone screen, run interview loops, and debrief, and some tips for interviewers and hiring managers....