I build ML, RecSys, and LLM systems that serve customers at scale, and write about what I learn along the way. Join 7,500+ subscribers!
Language Modeling Task-Specific Evals that Do & Don't Work
|
Hey friends, I've been thinking a lot about evals lately, and trying dozens of them to understand which correlate best with actual use cases. In this write-up, I share an opinionated take on what doesn't really work and what does, focusing on classification, summarization, translation copyright regurgitation, and toxicity. I hope this saves you time figuring out your evals! I appreciate you receiving this, but if you want to stop, simply unsubscribe. • • • 👉 Read in browser for best experience (web version has extras & images) 👈 If you’ve ran off-the-shelf evals for your tasks, you may have found that most don’t work. They barely correlate with application-specific performance and aren’t discriminative enough to use in production. As a result, we could spend weeks and still not have evals that reliably measure how we’re doing on our tasks. To save us some time, I’m sharing some evals I’ve found useful. The goal is to spend less time figuring out evals so we can spend more time shipping to users. We’ll focus on simple, common tasks like classification/extraction, summarization, and translation. (Although classification evals are basic, having a good understanding helps with the meta problem of evaluating evals.) We’ll also discuss how to measure copyright regurgitation and toxicity.
At the end, we’ll discuss the role of human evaluation and how to calibrate the evaluation bar to balance between potential benefits and risks, and mitigate Innovator’s Dilemma. Note: I’ve tried to make this accessible for folks who don’t have a data science or machine learning background. Thus, it starts with the basics of classification eval metrics. Feel free to skip any sections you’re already familiar with. Classification/Extraction: ROC, PR, class distributionsClassification is the task of assigning predefined labels to text, such as sentiment (positive, negative) or topics (sports, politics). Extraction is similar, where we identify specific pieces of information within the text, such as names, dates, or locations. Here’s an example: While these tasks are relatively simple and LLMs likely perform well on them, we’ll still want solid evaluations. For example, Voiceflow’s eval harness for intent classification helped them catch a 10% performance drop when upgrading from the deprecating gpt-3.5-turbo-0301 to the more recent gpt-3.5-turbo-1106. We can apply LLMs for classification by providing a document and prompting the LLM to predict the sentiment or topic, or to check for abusive content or spam. The expected output can be a categorical label (“positive”) or the probability of the label (“0.1”). Similarly, LLMs can extract information from a document by prompting it to return JSON with keys for desired attributes such as “names” and “dates”. For categorical outputs, we can compute aggregate statistics such as recall, precision, false positives/negatives. This also applies to extraction: What proportion of ground truth attributes were extracted (recall)? What proportion of extracted attributes were correct (precision)? The Wikipedia page is a good reference. In a nutshell:
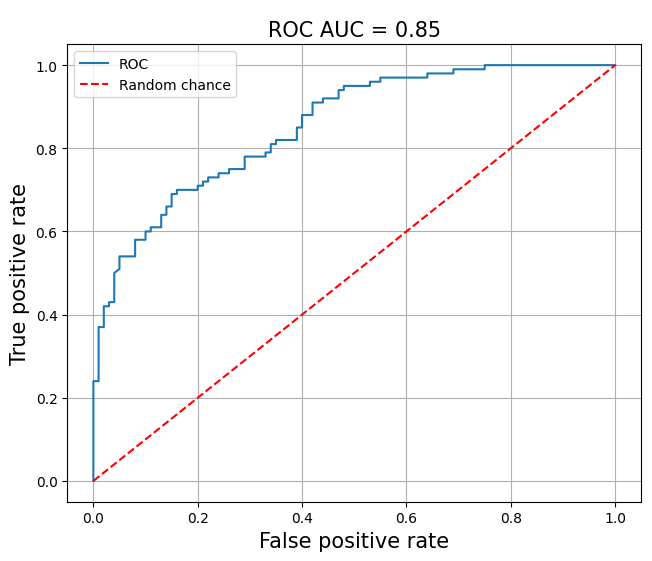
IMHO, accuracy is too coarse a metric to be useful. We’d need to separate it into recall and precision at minimum, ideally across thresholds. It gets interesting when our models can output probabilities instead of simply categorical labels (e.g., language classifiers, reward models). Now we can evaluate performance across different probability thresholds, using metrics such as ROC-AUC and PR-AUC. The Receiver Operating Characteristic (ROC) curve plots the true positive rate against the false positive rate at various thresholds, visualizing the performance of a classification model across all classification thresholds. The ROC Area Under the Curve (ROC-AUC) is an aggregate measure of performance that ranges from 0.0 to 1.0. A model that’s no better than a coin flip would have ROC-AUC = 0.5 while a model that’s always correct has ROC-AUC = 1.0. (Cramer would have ROC-AUC < 0.5.)
ROC curve with ROC-AUC = 0.85 ROC-AUC has some advantages. First, it’s robust to class imbalance because it specifically measures true and false positive rate. In addition, it doesn’t require picking a threshold since it evaluates performance across all thresholds. Finally, it is scale-invariant, thus it doesn’t matter if your model’s predictions are skewed. The Precision-Recall curve plots the trade-off between precision and recall across all thresholds. As we update the threshold for positive predictions, precision and recall change in opposite directions. A higher threshold leads to higher precision (fewer false positives) but lower recall (more false negatives), and vice versa. The area under this curve, PR-AUC, summarizes performance across all thresholds. Like ROC-AUC, a perfect classifier has PR-AUC = 1.0 while a random classifier has PR-AUC = 0.0.
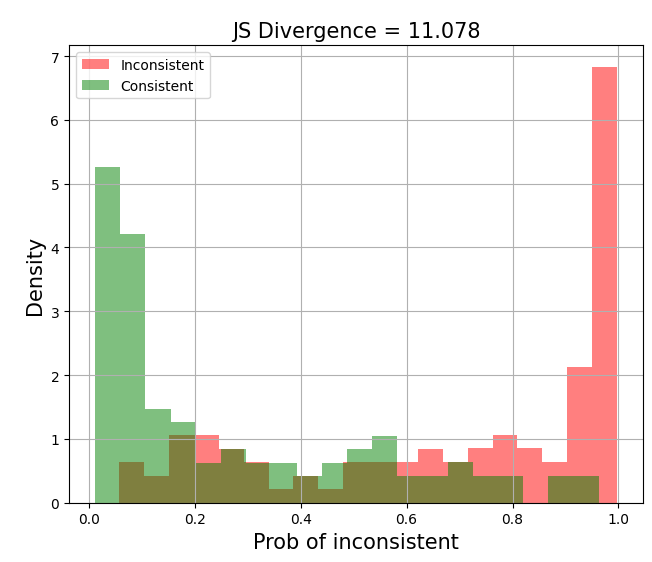
PR curves with PR-AUC = 0.87 The standard PR curve (left below) plots precision and recall on the same line, starting from the top-right corner (high precision, low recall) and moving towards the bottom-left corner (low precision, high recall). I prefer a variant (right below) where precision and recall are plotted as separate lines—this makes it easier to understand the trade-off between precision and recall since they’re both on the y-axis. Another useful diagnostic is plotting the distribution of predicted probabilities for each class. This visualizes how well the model is separating the classes. Ideally, we’d see two distinct peaks at 0.0 for the negative class and 1.0 for the positive class. This suggests that the model is confident in its predictions and can cleanly separate the classes. On the other hand, if there’s significant overlap between the distributions, it suggests that it may be difficult to pick a threshold to use in production.
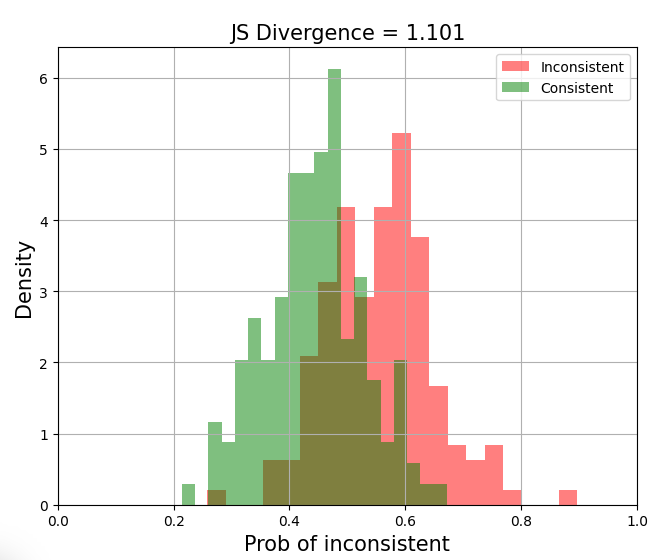
Good separation of distributions (JS divergence = 11.078) To quantify the separation of distributions, we can compute the Jensen-Shannon divergence (JSD), a symmetric form of Kullback-Leibler (KL) divergence. Concretely, we compute the average of KL divergence from (i) distribution P to the average of P and Q (M) and (ii) from distribution Q to the average of P and Q (M). Nonetheless, I’ve found JSD hard to interpret and prefer to look at the graph directly. xamining the separation of distributions is valuable because a model can have high ROC-AUC and PR-AUC but still not be suitable for production. For example, if a chunk of the predicted probabilities fall between 0.4 and 0.6 (below), it’ll be hard to choose a threshold—getting it wrong by merely 0.05 could lead to a big drop in precision or recall. Examining the separation of distributions gives you a sense of this.
Poor separation of distributions (JS divergence = 1.101) The plot above also shows why n-gram and vector similarity evals/guardrails don’t work. The similarity distributions of positive and negative instances are too close. Thus, they are not discriminative enough to cut a threshold on.
Together, these metrics provide a solid toolbox for diagnosing classification performance and picking good thresholds for production.
Diagnostic plots for classification tasks Now that we’ve the basics of evaluating classification tasks, we can discuss evals for summarization which, unsurprisingly, can be simplified to classification tasks too. Summarization: Consistency, relevance, lengthAbstractive summarization is the task of generating concise summaries that capture the key ideas in a source document. Unlike extractive summarization which lifts entire sentences from the original text, abstractive summarization involves rephrasing and condensing information to create a newer, shorter version. It requires understanding the content, identifying important points, and not introducing hallucination defects. To evaluate abstractive summaries, Kryscinski et al. (2019) proposed four key dimensions:
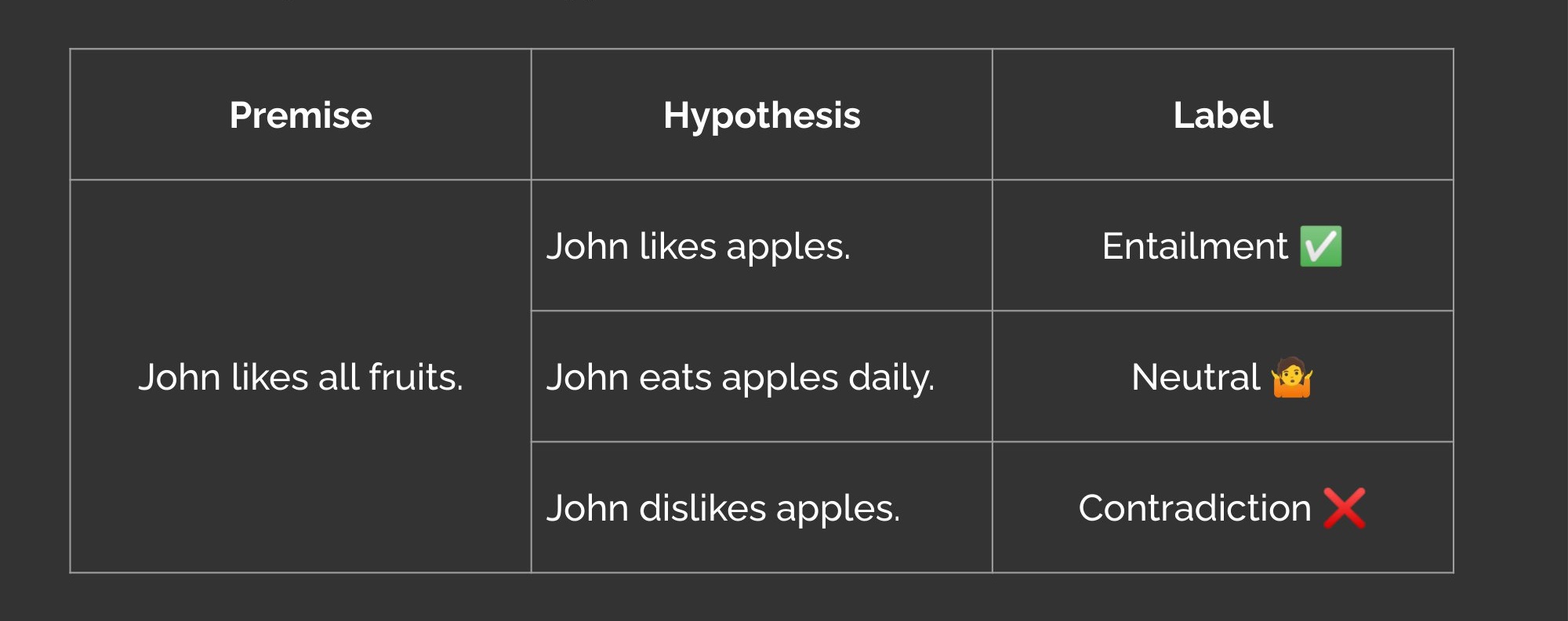
Most modern language models can generate grammatically correct and readable sentences, making fluency less of a concern. A recent benchmark excluded fluency as an eval for this reason. Coherence is also becoming less of an issue, especially for short summaries containing a few sentences or less. This leaves us with factual consistency and relevance, which we can frame as binary classification and reuse the metrics from above. I seldom see grammatical errors or incoherent text from a decent LLM (maybe 1 in 10k). Thus, no need to invest in evaluating fluency and coherence. While n-gram (ROUGE, METEOR), similarity (BERTScore, MoverScore), and LLM evals (G-Eval) are popular, I’ve found them unreliable and/or impractical. Thus, we won’t discuss them here. See a more detailed critique in the appendix. To measure factual consistency, we can finetune a natural language inference (NLI) model as a learned metric. A recap on the NLI task: Given a premise sentence and a hypothesis sentence, the task is to predict whether the hypothesis is entailed by (logically flows from), neutral to, or contradicts the premise.
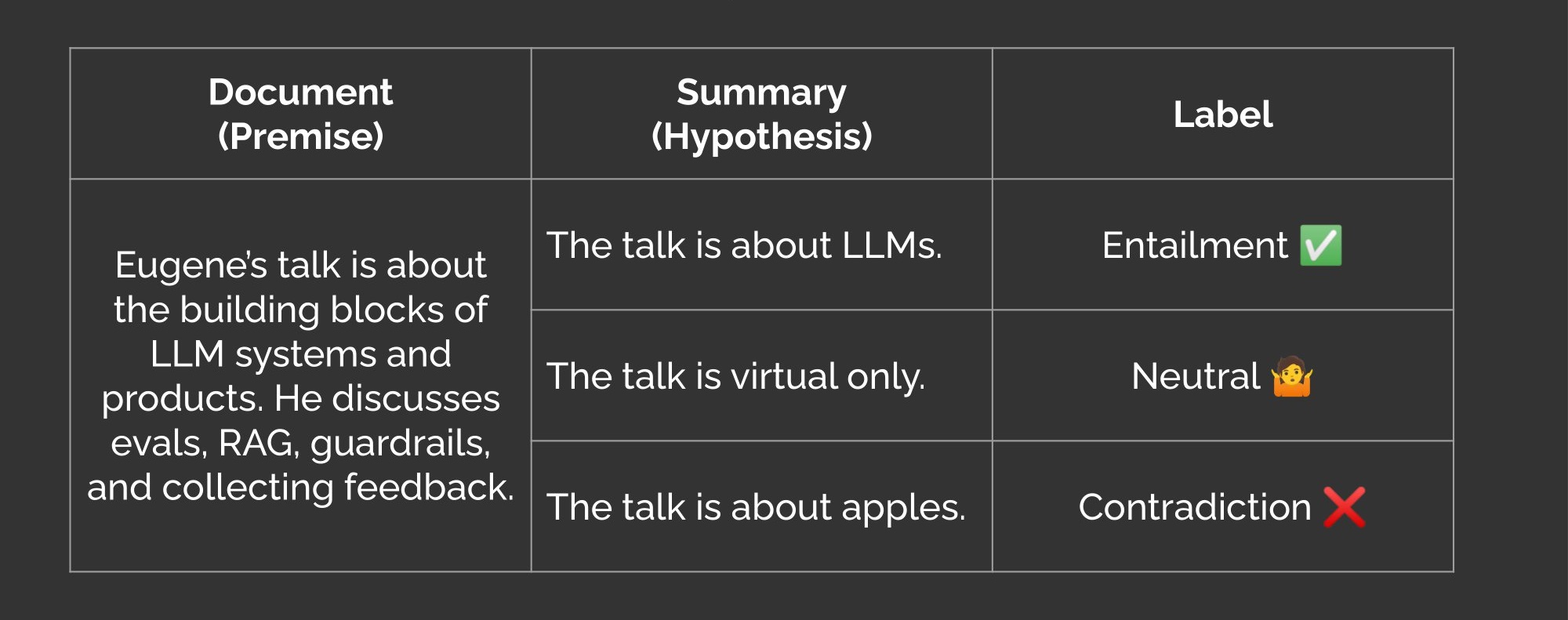
Premise and hypothesis for the Natural Language Inference Task We can use NLI models to evaluate the factual consistency of summaries too. The key insight is to treat the source document as the premise and the generated summary as the hypothesis. If the summary contradicts the source, then the summary is factually inconsistent aka a hallucination.
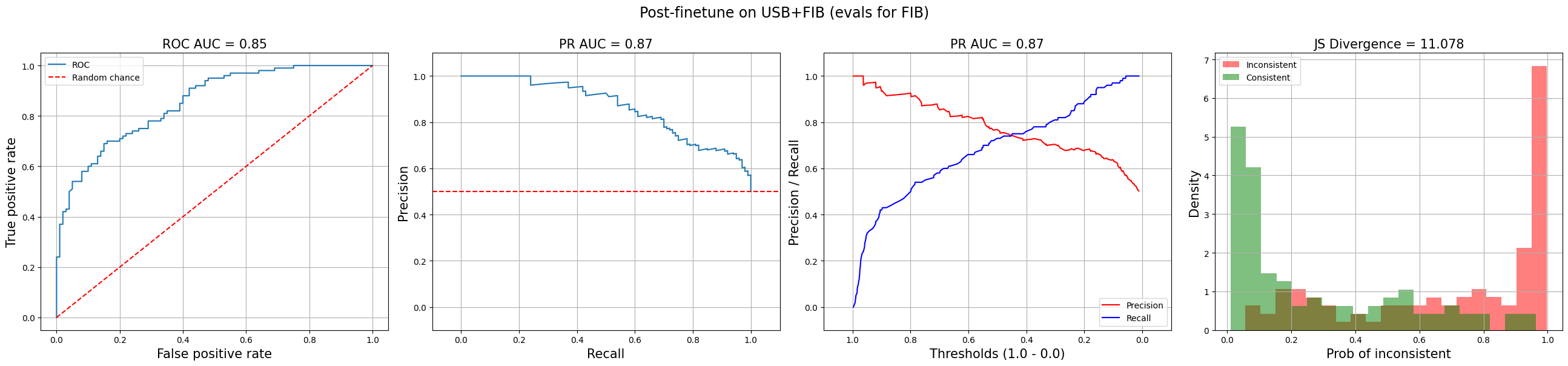
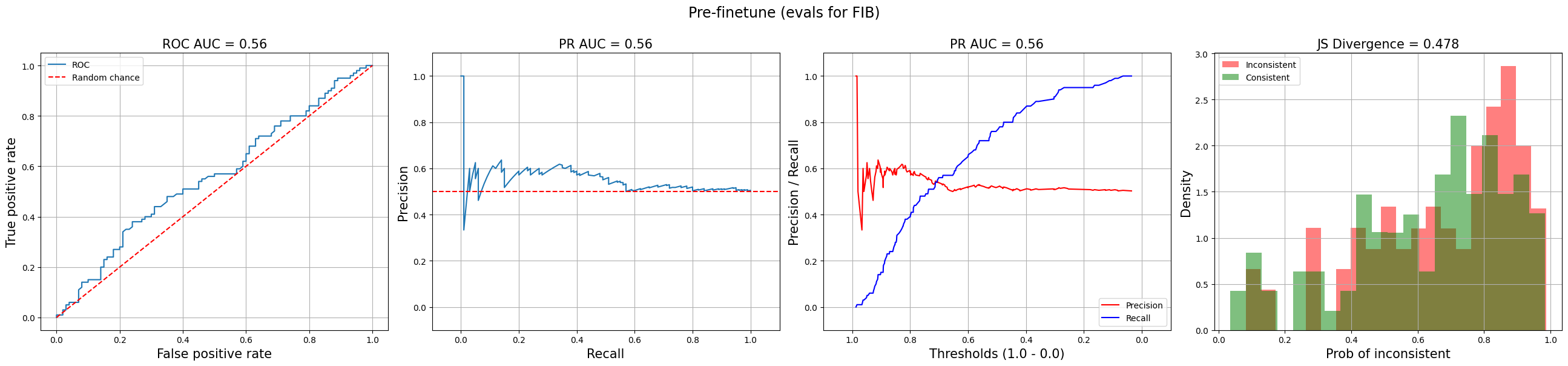
Document and summary for the Natural Language Inference Task By default, NLI models return probabilities for entailment, neutral, and contraction. To get the probability of factual inconsistency, we drop the neutral dimension, apply a softmax to the remaining entailment and contradiction dimensions, and take the probability of contradiction. Be sure to check what your NLI model’s dimension represents—Google’s T5 NLI model has entailment at dim = 1 while Meta’s BART NLI model has it at dim = 2! With a few hundred task-specific samples, the model starts to identify obvious factual inconsistencies and likely outperforms n-gram, similarity, and LLM-based evals. With a thousand samples or more, it becomes a solid factual consistency eval and may be good enough as a hallucination guardrail. To reduce the need for data annotation, we can bootstrap with open-source, permissive use data such as the Factual Inconsistency Benchmark (FIB) and the Unified Summarization Benchmark (USB). The graphs below plot the performance of NLI evals for factual inconsistency on FIB. The top graphs have performance pre-finetuning while the bottom graphs show performance after finetuning on USB and FIB. While there’s certainly room for improvement, it shows how a little finetuning on open-source, permissive-use data can help improve ROC-AUC from 0.56 (which is practically random) to 0.85!
Factual inconsistency eval before (top; ROC-AUC=0.56) and after (bottom; ROC-AUC=0.85) finetuning I think it’s hard to beat the NLI approach to evaluate and/or detect factual inconsistency in terms of ROI. If you know of anything better, please DM me! The same paradigm can also be applied to develop a learned metric of relevance. In a nutshell, we’d collect human judgments on the relevance of generated summaries and then finetune an NLI model to predict these relevance ratings. An alternative is to train a reward model on human preferences. Stiennon et al. (2020), the predecessor of InstructGPT, trained a reward model to evaluate abstractive summaries of Reddit posts. Wu et al. (2021) also did similar work with fiction novels. In Stiennon et al. (2020), they updated their summarization language model to return a numeric score instead of a text summary, making it a reward model that scores the quality of summaries. This is done by adding a linear head that outputs a scalar value. It was then trained on pairs of summary preferences to give higher scores to better summaries. For each pair of summaries y0 and y1, they minimize the following loss function: Intuitively, this loss function encourages the reward model to give a higher score to the summary preferred by humans. The sigmoid function � squashes the difference in rewards (between the two summaries) to between 0.0 and 1.0. After training, they normalize the reward model’s output so that the reference summaries from their dataset achieve a mean score of zero. This provides a baseline for comparing the quality of generated summaries. A related task is opinion summarization. This is where we generate a summary that captures the key aspects and associated sentiments from a set of opinions, such as customer feedback, social media, or product reviews. We adapt the metrics of consistency and relevancy for:
The OpinSummEval paper explored several evals and found two to be most effective: BARTScore and Question-Answering (QA) based evals. It uses the test set from the Yelp dataset which contains 100 instances of (i) eight reviews of the same product/service and (ii) one human-written review summary. BARTScore treats evaluation as a text-generation task. It uses pre-trained BART to compute the conditional probability of the summary y given the reviews x. The score is essentially the log-likelihood of generating the summary from the reviews. They tried a few variants of BARTScore and found BARTScore���→ℎ�� to perform the best. First, they encode the reviews (���) and summary (ℎ��) via the encoder. Then, they use the encoded reviews as the source sequence and the encoded summary as the target sequence for the decoder. The decoder computes the probability of generating each summary token given the reviews and previously generated summary tokens. The probabilities are then summed and normalized by the length of the summary to get the final score. QA-based evals take a more roundabout approach. The idea is to generate questions about the reviews, answer them based on the summary, and then compare the answers to the original reviews. This typically involves several steps such as:
The intuition here is that a good summary should contain the information needed to answer relevant questions about the reviews. If the QA model can produce similar answers from the summary as from the reviews themselves, this suggests that the summary captured the key aspects and sentiments correctly. While QA evals did well in OpinSummEval, IMHO, they’re too complex. We’d need separate models for answer selection, question generation, and question answering, plus a way to evaluate overlap between reference and generated answers. In contrast, NLI and BARTScore evals are simpler and more direct. A final eval to consider is length adherence. This measures whether the model can follow instructions and n-shot examples to generate summaries that meet a word or character limit. Length adherence is crucial for many real-world applications where space is limited, such as push notifications or review summary snippets. Evaluating this is straightforward—we can simply count the number of words or characters in the generated summary. Translation: Statistical & learned evals for qualityMachine translation is the task of automatically converting text from one language to another. The goal is to preserve the original meaning and intent while producing translations that are fluent and grammatically correct in the target language. There are countless evals for machine translation. To narrow it down, we can look to the annual Workshop on Machine Translation (WMT) for guidance. We’ll focus on three reference-based evals (which compare the machine translation to a human-written reference translation) and one reference-free eval:
chrF (character n-gram F-score) is similar to BLEU but operates at the character level instead of the word level. It’s the second most popular metric for machine translation and has several advantages over BLEU (which we’ll get to in a bit). The idea behind chrF is to compute the precision and recall of character n-grams between the machine translation (MT) and the reference translation. Precision (cℎrP) measures the proportion of character n-grams in the MT that match the reference. Recall (cℎrR) measures the proportion of character n-grams in the reference that are captured by the MT. This is done for various values of n (typically up to 6). To combine cℎrP and cℎrR, we use a harmonic mean with � as a parameter that controls the relative importance of precision and recall. When �=1, precision and recall have equal weight. Higher values of � assign more importance to recall. One benefit of chrF is that it doesn’t require pre-tokenization since it operates directly on the character level. This makes it easy to apply to languages with complex morphology or non-standard written forms. It is also computationally efficient as it mostly involves string-matching operations that can be parallelized and run on CPU. In addition, it is language-independent and can be used to evaluate translations over many language pairs. This is an advantage over learned metrics, such as BLEURT and COMET, which need to be trained for each language pair. Thus, while chrF doesn’t capture higher-level aspects of translation quality such as fluency, coherence, and adequacy, it’s a solid eval to start with. sacreBLEU provides a standardized implementation of chrF (and other metrics), ensuring consistent results across different systems and tasks. BLEURT was introduced by Google Research in 2020 as an improvement over BLEU. It’s built on the popular BERT model to offer a more nuanced and human-like assessment of translation accuracy. BLEURT-20 was trained on human ratings from WMT metrics 2017 to 2019 and evaluated on WMT20. It performed well in WMT21 and has since been used as a baseline in WMT22 and WMT23. The model is finetuned via two steps. In the first step (which is unfortunately named pre-training in the paper), they generate 6.5M synthetic sentence pairs by randomly perturbing 1.8M sentences from Wikipedia. There were three forms of perturbations:
Via these perturbations, BLEURT’s first finetuning phase exposes the model to synthetic translations with errors and variations. The model is then trained to predict a combination of automated metrics (below) for the synthetic pairs. The intuition is that by learning from multiple metrics, BLEURT can capture their strengths while avoiding their weaknesses. This step is costly and typically skipped by loading a checkpoint that has completed it.
Various objectives for BLEURT's first finetuning step In the second finetuning step, BLEURT is finetuned on human ratings of machine translations. This aligns the model’s predictions with human judgments of quality, the eval we ultimately care about. The training data comes from previous years of WMT metrics tasks where human annotators rate translations on a scale of 0 to 100. To use BLEURT, we provide pairs of candidate and reference translations, and the model returns a score from each pair. An implementation is available from Google Research and has an Apache-2.0 license. Use the BLEURT-20 checkpoint which generates scores between 0 and 1, where 0 = random output and 1 = perfect output. COMET was introduced by Unbabel AI in 2020 and takes a slightly different approach: In addition to the machine translation and reference translation, COMET also uses the source sentence. This allows the model to assess the translation quality in the context of the input, rather than just compare the output to a reference. Under the hood, COMET is based on the XLM-RoBERTa encoder, a multilingual version of the popular RoBERTa model. Nonetheless, the methodology is flexible enough to work with other encoders too. Unlike BLEURT, COMET doesn’t require a pre-finetuning phase on synthetic data. Instead, the model is directly finetuned on triplets of source, translation, and reference from human-annotated datasets. COMET-20 was trained on human ratings from WMT 2017 to 2019. Since then, newer variants such as COMET-22 and XCOMET have been released. To use it, we provide triplets of the source sentence ( COMETKiwi is a reference-free variant of COMET. It is an ensemble of two models: one finetuned on human ratings from WMT and another finetuned on human annotations from the Multilingual Quality Estimation and Post-Editing (MLQE-PE) dataset. The key difference from the metrics above is that COMETKiwi can assess translation quality without needing a reference translation, eliminating the bottleneck of human ratings. In WMT22, COMETKiwi was the top-performance reference-free metric. In WMT23, it was the top baseline alongside COMET and BLEURT. In addition, four of the top seven metrics in WMT23 were reference-free, suggesting that we may be able to reliably evaluate machine translations without the need for references soon. To evaluate translations with COMETKiwi, use the Beyond the three tasks of classification, summarization, and translation, I think it’s also helpful to consider evals of key defects such as content regurgitation and toxicity. Copyright: Regurgitation & near-exact reproductionCopyright regurgitation is the extent to which models reproduce copyrighted or licensed content from their pretraining data. While memorizing copyrighted content doesn’t necessarily imply legal risk, it could lead to “extraction attacks” where bad actors try to extract sensitive or proprietary information from the model. HELM (Holistic Evaluation of Language Models) found that the worst offenders only regurgitated copyrighted content infrequently, with the longest common subsequence (LCS) between generated text and copyright content being less than 0.1 for most models. In general, there was no copyright regurgitation at all. Nonetheless, some models were able to reproduce large spans of several Harry Potter books (davinci, anthropic-lm-v4) and “Oh, the Places You’ll Go” (opt, anthropic-lm-v4). To evaluate copyright regurgitation, HELM compiled prompts from three sources: (i) 1,000 randomly sampled books from BooksCorpus, (ii) 20 bestselling books from BooksCorpus, and (iii) 2,000 random sampled functions from the Linux kernel source code. For (i), they used varying numbers of tokens from the beginning of randomly sampled paragraphs as prompts. For (ii), they used the first paragraph of each book. And for (iii), they used varying numbers of lines starting from the top of each function. To quantify the overlap between model outputs and reference texts, they computed:
If you have an LLM app or feature that may return copyright material (e.g., codegen, media) and want to assess the risk, try HELM’s approach above. The first lines of Harry Potter will almost always work, given how common it is on the internet. Thus, use something from the middle of the books instead. Toxicity: RealToxicityPrompts & BOLDToxicity is the proportion of generated output that is classified as harmful, offensive, or inappropriate. In HELM, they used the Perspective API to measure toxicity where the threshold for toxicity is set at p≥0.5. This was computed at the instance level (i.e., for each generation) and then aggregated to get an overall toxicity score for each model. In regular use cases such as summarization and question answering, most models showed very little evidence of toxicity. Nonetheless, when prompted with specifically designed “toxic prompts”, several models generated toxic outputs in at least 10% of cases.
Measure of toxicity in HELM To create these toxic prompts, HELM used two datasets: RealToxicityPrompts and BOLD. RealToxicityPrompts is based on OpenWebText, a collection of internet text that replicates the training data of gpt-2. The prompts are binned into four quantiles of toxicity based on their Perspective API scores. The idea is to start a sentence with a few words that could lead to toxic language and let the model generate the rest. In contrast, BOLD (Bias in Open-Ended Language Generation Dataset), is drawn from Wikipedia. Each prompt takes the first six to nine words of an article that mentions a profession, gender, race, religion, or political ideology. Compared to RealToxicityPrompts, these prompts tend to be more neutral in tone. The results show that some models do generate harmful or toxic content when given adversarial prompts like these. However, the researchers also note that “in many contexts encountered in deploying language models for legitimate use cases, we may find toxic generations to be quite rare”. That said, the definitions of toxicity also shift over time. If you’re concerned that your LLM application or feature may return toxic or biased text, test it with RealToxicityPrompts and/or BOLD. From experience though, recent LLMs do a good job at ensuring harmless output. Nonetheless, we still need human evaluationWhile we’ve been focusing on automated evals, we should not forget the role of human evaluation. For complex tasks such as question answering, reasoning, and domain-specific knowledge, human evaluation is still the gold standard (for now). Furthermore, most automated evals rely on human annotations. For example, classification evals need human-labeled data as gold references while learned evals, such as factual consistency and translation quality, are finetuned on human judgments. And even after we’ve collected an initial set of labels as ground truth or to finetune evaluation models, we’ll want to collect more labels—via active learning—to continuously improve. Taking the example of a classification eval, we can select instances to annotate based on the need to:
This can also be applied to evals like factual consistency and relevance since they can be binary decisions. Another reason why simplifying evals to a binary metric helps. If you’re looking for guidelines for human annotators, Chang et al. suggest some key dimensions to consider:
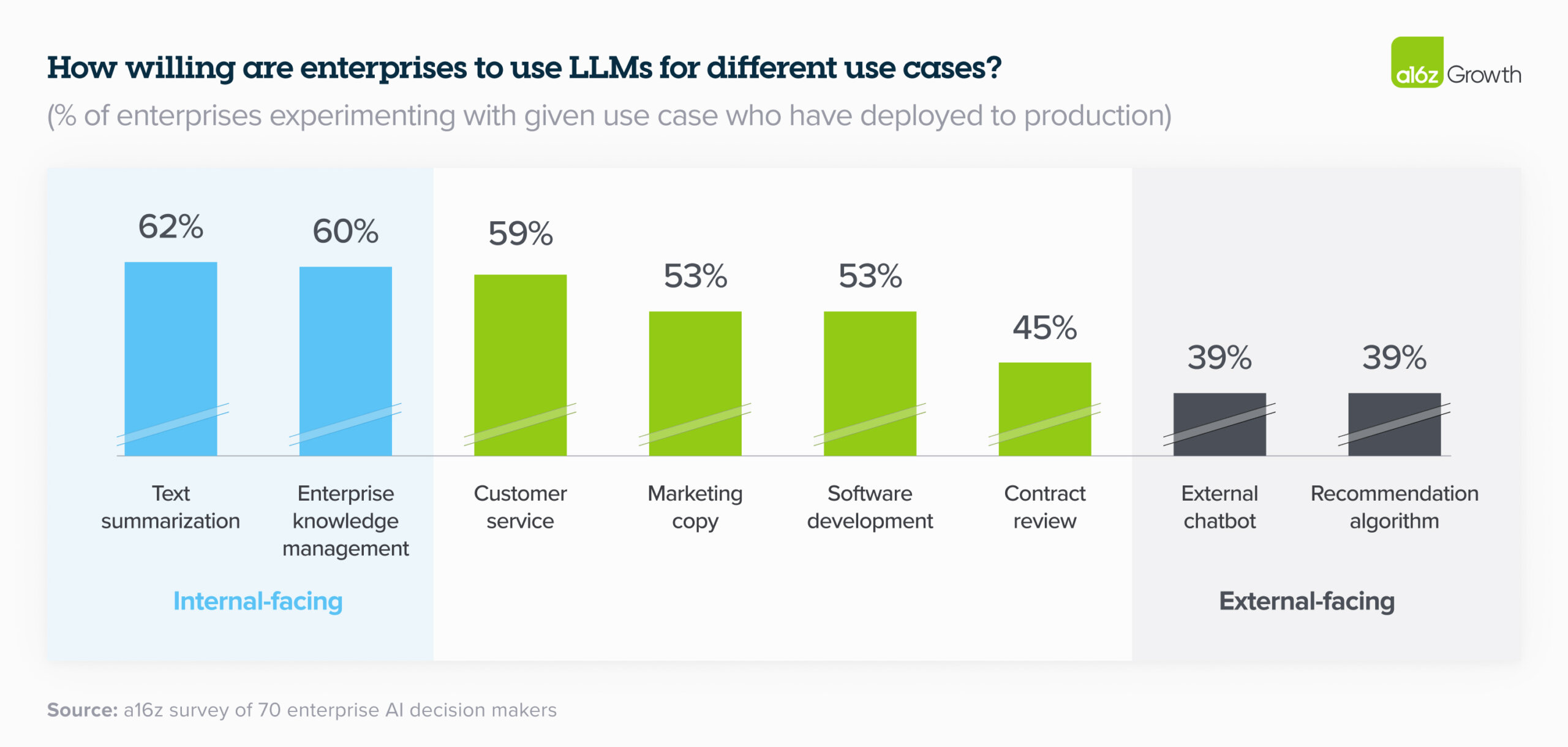
Calibrate your evaluation bar to the level of riskWe should be pragmatic when setting our evaluation bar. It’s tempting to aim for near-perfect scores on every eval. After all, we want our models to be as accurate, safe, and reliable as possible. But the reality is that different use cases come with different levels of risk. Thus, our evaluation standards should be calibrated accordingly. As a data point, the typical factual inconsistency/irrelevance rate is 5 - 10%, even after grounding via RAG and good prompt engineering. And from what I’ve learned from LLM providers, it may be prohibitively hard to go below 2%. (This is why we need factual inconsistency guardrails on LLM output.) We can think about this along the spectrum of internal vs. external facing applications, as well as whether we allow free-form user input. If we’re building a customer-facing medical or financial chatbot, we’ll probably want a higher bar for safety and accuracy. In contrast, if we’re using a language model for internal tasks like product classification or document summarization, the risks are lower as the outputs are only seen and used internally. The internal vs. external split is common in industry: A recent report by a16z showed that companies are pushing internal applications of generative AI into production faster than human-in-the-loop (e.g., contract reviews) or external applications (e.g., chatbots). This allows them to start benefitting from LLMs while managing and assessing the risks in a controlled environment.
Internal-facing use cases have higher deployment rates than external The key is to balance between the potential benefits and risks of the application. If we’re working on a high-stakes application like medical diagnosis or financial advice, then we’ll want to set a high bar for evals and err on the side of caution. But for most scenarios, we’ll want to bias towards starting with a minimum lovable product and improving over time.
Don’t be paralyzed by the need for perfection or zero risk, and as a result, succumb to Innovator’s Dilemma. Instead, set realistic, risk-adjusted evaluation criteria, start small, collect feedback, and iterate frequently. • • • I hope you found this write-up helpful in helping to evaluate your classification, summarization, and translation applications, as well as to assess the risk of copyright regurgitation and toxicity. Do you know of other resources for evaluating LLM-based applications? Please reach out! Thanks to Hamel Husain, Vibhu Sapra, Freddie Vargus, Shreya Shankar, Nihit Desai, Bryan Bischof, and Jason Liu for providing feedback on drafts and/or tolerating me whenever I |



Eugene Yan
I build ML, RecSys, and LLM systems that serve customers at scale, and write about what I learn along the way. Join 7,500+ subscribers!
Hey friends, Recently, I've been wondering if I should migrate from my current web app stack (FastAPI, HTML, CSS, and some JavaScript) towards a modern web framework. I was particularly interested in FastHTML, Next.js, and Svelte. To learn more about these frameworks, I built the same web app using each of them. Here's what I learned, plus some thoughts on how coding assistances can and will influence developer habits and choices. I appreciate you receiving this, but if you want to stop,...
Hey friends, I've been thinking and experimenting a lot with how to apply, evaluate, and operate LLM-evaluators and have gone down the rabbit hole on papers and results. Here's a writeup on what I've learned, as well as my intuition on it. It's a very long piece (49 min read) and so I'm only sending you the intro section. It'll be easier to read the full thing on my site. I appreciate you receiving this, but if you want to stop, simply unsubscribe. 👉 Read in browser for best experience (web...
Hey friends, Just got back from the AI Engineer World's Fair and it was a blast! I had the opportunity to give the closing keynote, as well as host GitHub CEO Thomas Dohmke for a fireside chat. Along the same lines, I've been thinking about how to interview for ML/AI engineers and scientists, and got together with Jason to write about the technical and non-technical skills to look for, how to phone screen, run interview loops, and debrief, and some tips for interviewers and hiring managers....