I build ML, RecSys, and LLM systems that serve customers at scale, and write about what I learn along the way. Join 7,500+ subscribers!
Out-of-Domain Finetuning to Bootstrap Hallucination Detection
Hey friends,
This week we dig into an interesting finding where finetuning on Wikipedia data actually helps with detecting hallucinations on news data. We'll go through it stage-by-stage and evaluate the model after each step to get a better understanding of what happens. I hope you'll find this as exciting to read and it was for me when I ran the experiments.
P.S., The recording for my ai.engineer talk was just released! You can watch it here.
I appreciate you receiving this, but if you want to stop, simply unsubscribe.
• • •
👉 Read in browser for best experience (web version has extras & images) 👈
It’s easy to finetune models for our specific tasks; we just need a couple hundred or a few thousand samples. However, collecting these samples is costly and time-consuming. What if, we could bootstrap our tasks with out-of-domain data? We’ll explore this idea here.
The task is to finetune a model to detect factual inconsistencies aka hallucinations. We’ll focus on news summaries in the Factual Inconsistency Benchmark (FIB). It is a challenging dataset—even after finetuning for 10 epochs on the training split, the model still does poorly on the validation split (middle in image below).
To examine how out-of-domain data helps, we re-instantiate our model and finetune on Wikipedia summaries for 3 epochs before finetuning for 10 epochs on FIB. This led to PR AUC of 0.85 (right below)—a 23% improvement over finetuning on FIB alone. Also, the probability distributions are better separated, making the model more suitable for production where we have to pick a threshold to classify a summary as inconsistent.
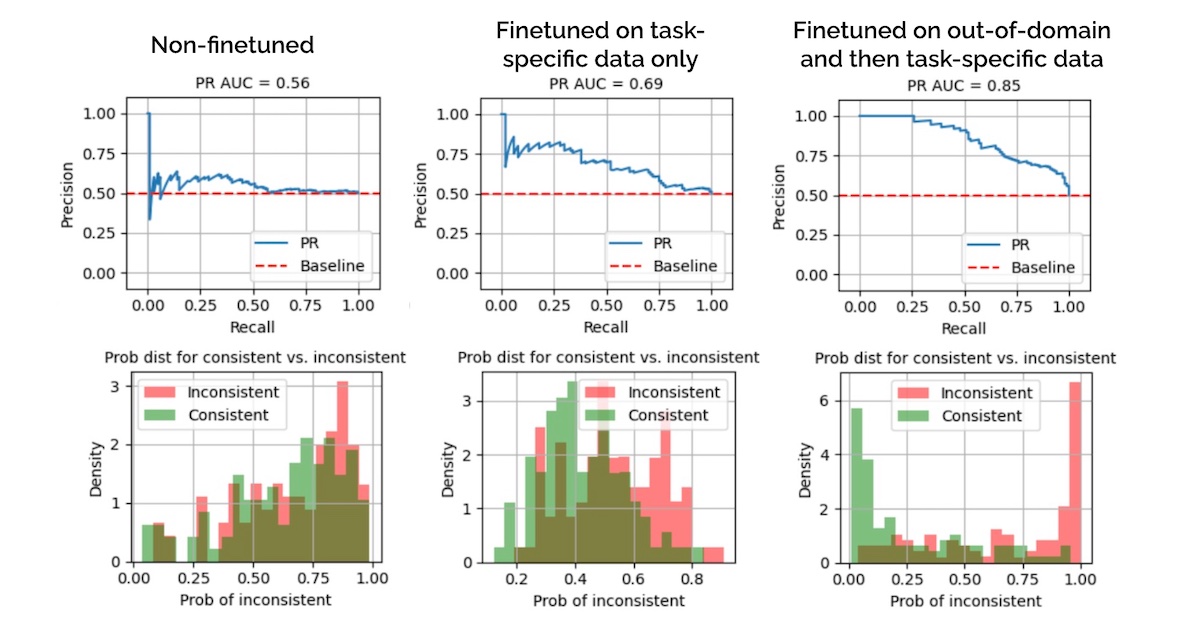 |
Evals on non-finetuned vs. task-specific finetuning vs. out-of-domain + task-specific finetuning
Okay, that was the high-level overview. Next, let’s dive into the details and visuals.
Classifying factual inconsistencies via NLI
We can detect factually inconsistent summaries via the natural language inference (NLI) task. The NLI task works like this: Given a premise sentence and a hypothesis sentence, the goal is to predict if the hypothesis is entailed by, neutral, or contradicts the premise.
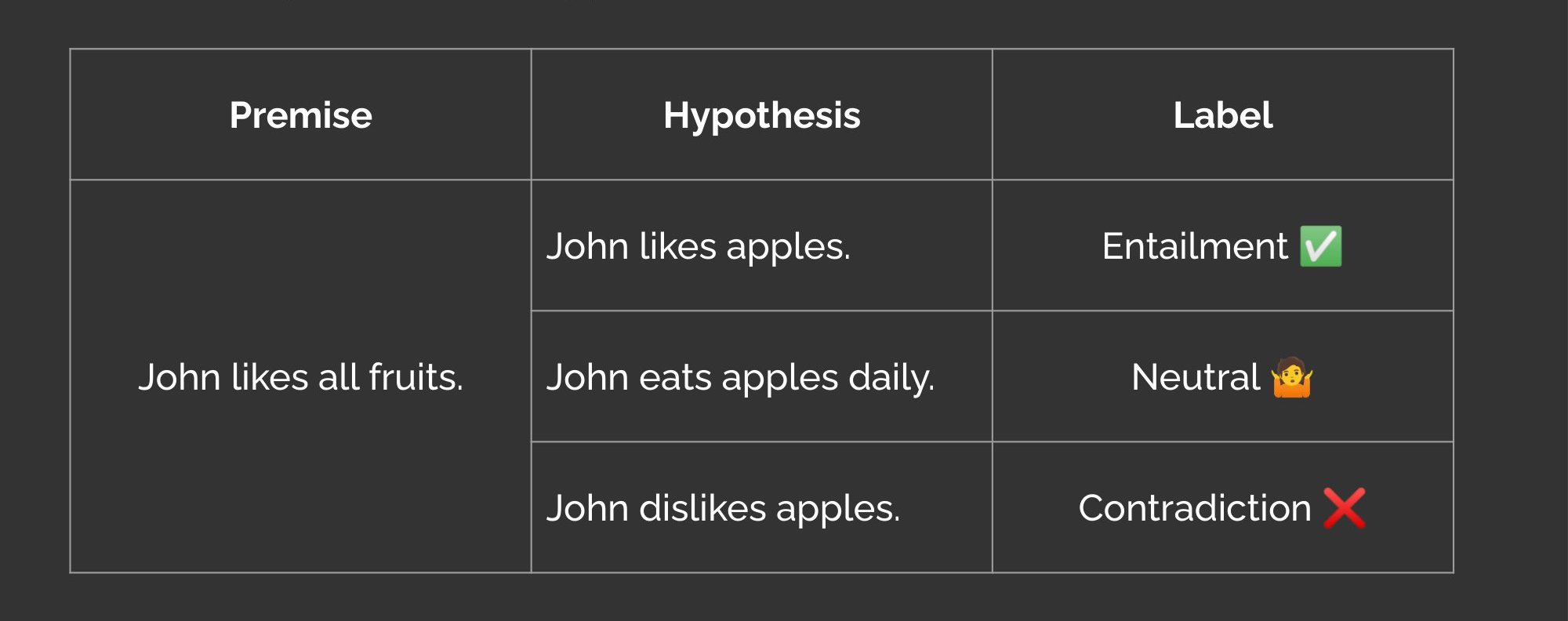 |
Entailment, neutral, and contradiction labels in NLI (source)
We can apply NLI to abstractive summaries too. Here, the source document is the premise and the summary is the hypothesis. Thus, if the summary contradicts the source, that’s a factual inconsistency aka hallucination.
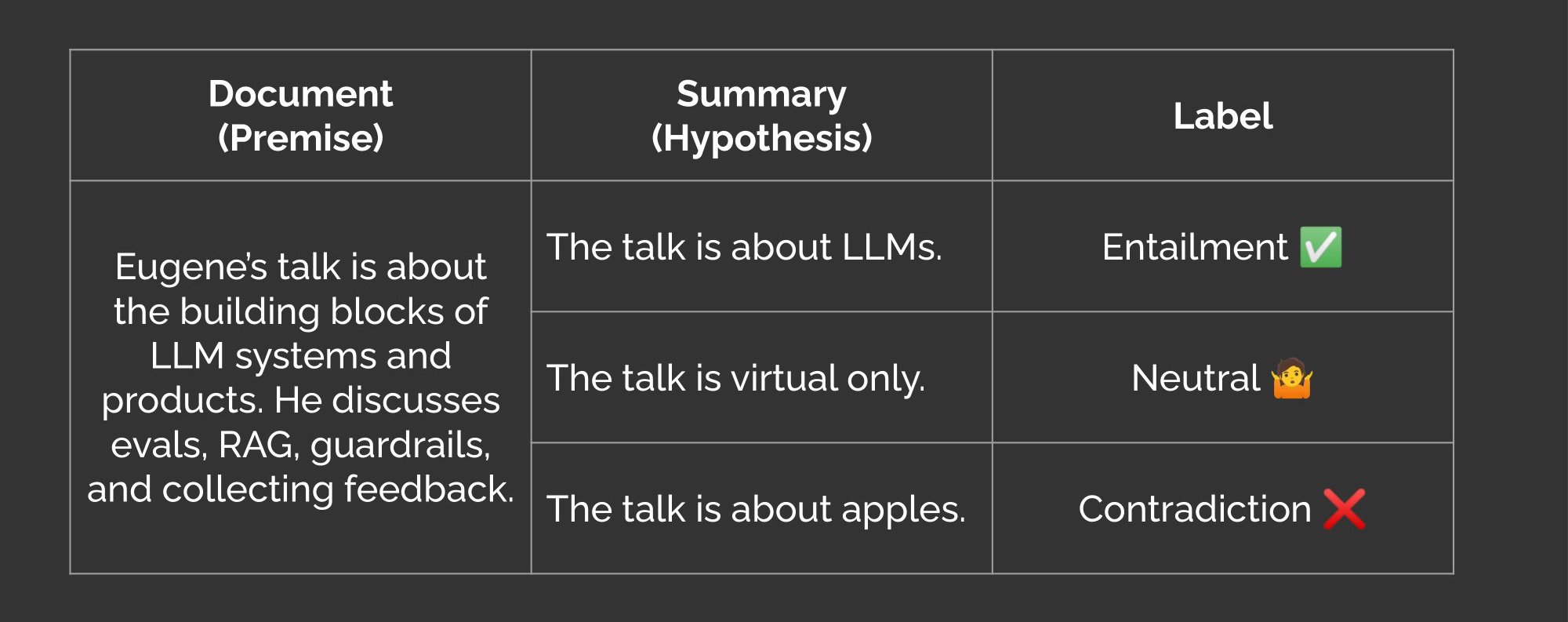 |
Entailment, neutral, and contradiction labels in abstractive summaries (source)
For the model, we’ll use a variant of BART that has been finetuned on the MNLI dataset. By default, an NLI model outputs probabilities for entailment (label = 2), neutral (label = 1), and contradiction (label = 0). To get the probability of factual inconsistency, we’ll drop the neutral dimension, apply a softmax on the remaining two dimensions, and take the probability of contradiction. It’s really just a single line of code:
Finetuning to classify factual inconsistencies in FIB
The Factual Inconsistency Benchmark (FIB) is a dataset for evaluating whether language models can spot factual inconsistencies in summaries. It is based on news summaries from CNN/Daily Mail and XSUM, with 100 and 500 news articles from each respectively. Each news article comes with a pair of summaries where one is factually consistent with the source document while the other isn’t.
Given a gold summary and a distractor, can we assign a higher score to the factually consistent summary vs. the factually inconsistent summary? (source)
Four of the authors annotated the summaries, and each summary was annotated by two annotators. First, they annotated reference summaries as factually consistent or inconsistent. Then, they edited the factually inconsistent summaries to be factually consistent with an emphasis on making minimal edits. Most edits involved removing or changing keywords or phrases that were not found in the news article.
To prepare for finetuning and evaluation, we first excluded the CNN/Daily Mail documents and summaries—they were found to be low quality during visual inspection. Then, we balanced the dataset by keeping one consistent summary and one inconsistent summary for each news article. Finally, we split it into training and validation sets, where validation made up 20% of the data (i.e., 100 news articles). To prevent data leakage, the same news article doesn’t appear across training and validation splits.
Upon visual inspection, it seems challenging to distinguish between consistent vs. inconsistent summaries. The latter tends to contain words from or similar to the source document but phrased to be factually inconsistent. Here’s the first sample in the dataset:
Evaluating the non-finetuned model on FIB confirms our intuition: The model struggled and had low ROC AUC and PR AUC (below). Furthermore, probability distributions for consistent vs. inconsistent summaries weren’t well separated—this makes it unusable in production where we have to pick a threshold to classify outputs as inconsistent.
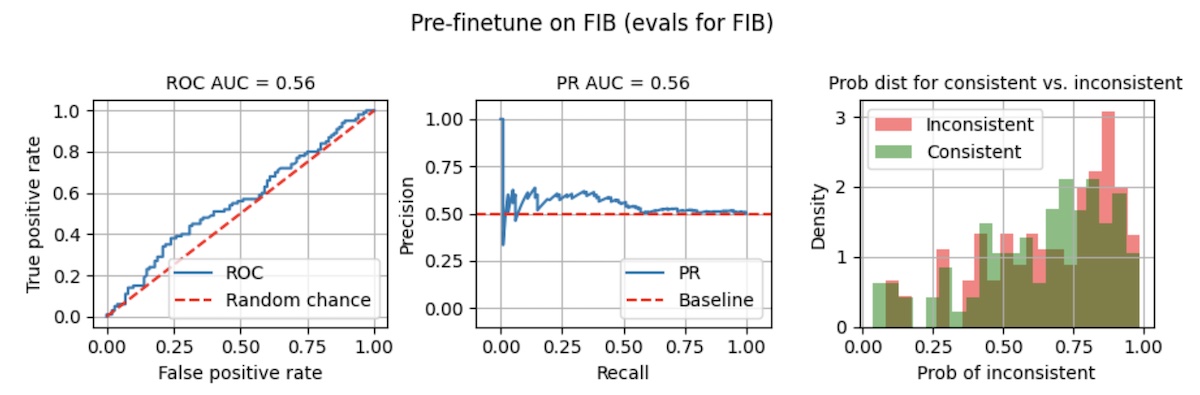 |
The non-finetuned model performs badly on FIB
After finetuning for 10 epochs via QLoRA, ROC AUC and PR AUC improved slightly to 0.68 - 0.69 (below). Nonetheless, the separation of probabilities is still poor. Taking a threshold of 0.8, recall is a measly 0.02 while precision is 0.67.
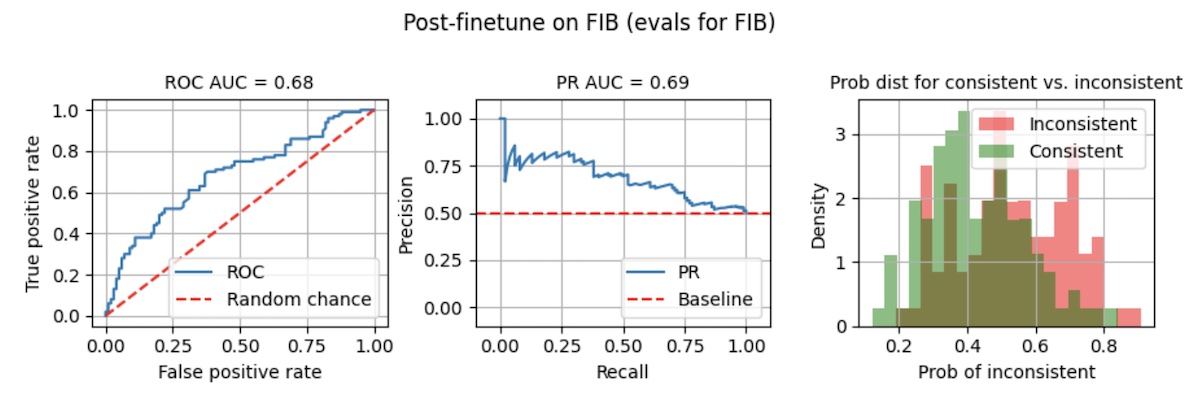 |
Even after finetuning for 10 epochs, performance isn't much better
Pre-finetuning on USB to improve performance on FIB
It seems that finetuning solely on FIB for 10 epochs wasn’t enough. What if we pre-finetune on a different dataset before finetuning on FIB?
The Unified Summarization Benchmark (USB) is made up of eight summarization tasks including abstractive summarization, evidence extraction, and factuality classification. While FIB documents are based on news, USB documents are based on a different domain—Wikipedia. Labels for factual consistency were created based on edits to summary sentences; inconsistent and consistent labels were assigned to the before and after versions respectively. Here’s the first sample in the dataset:
Nonetheless, the labeling methodology isn’t perfect. Summaries that were edited due to grammatical or formatting errors were also labeled as non-factual. For example, in the second sample, the only difference between the consistent and inconsistent summary is that the latter is missing the word “the”. IMHO, both summaries are factually consistent.
Cleaning the USB data is beyond the scope of this write-up so we’ll just use the data as is. (Surprisingly—or unsurprisingly—finetuning on the imperfect USB data was still helpful.) For the training and validation sets, we’ll adopt the split provided by the authors.
First, we re-instantiate the model before finetuning on the USB training split for 3 epochs with the same QLoRA parameters. Then, we evaluate on the FIB validation split.
Finetuning on USB data didn’t seem to help with the FIB validation split. (To be clear, we’ve not finetuned on the FIB data (yet) so the poor performance is expected.) ROC AUC and PR AUC barely improved (below), and the separation of probabilities appears just as bad. Taking the same threshold of 0.8, recall is 0.10 while precision is 0.59. Considering that the FIB data is balanced, precision of 0.59 is barely better than a coin toss.
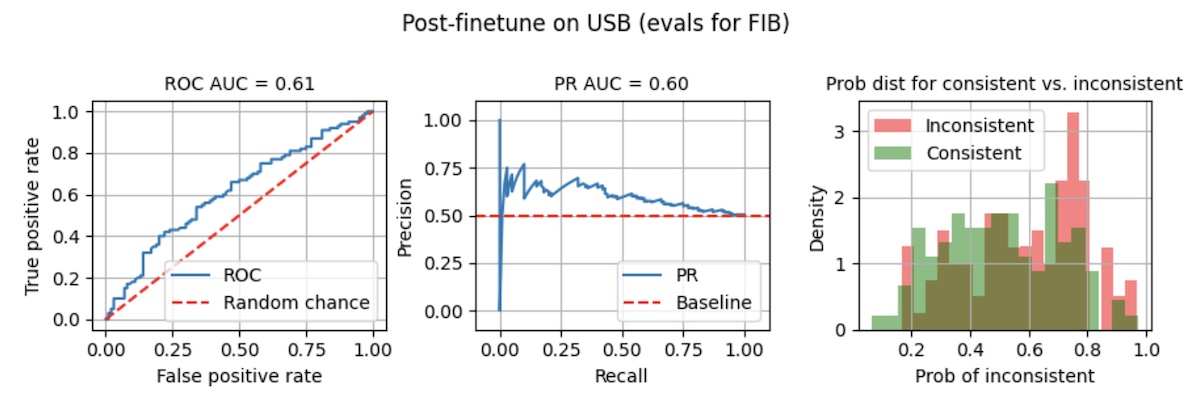 |
Finetuning on 3 epochs of USB didn't seem to help much with FIB...
But what happens when we add 10 epochs of finetuning on FIB? Our model now achieves PR AUC of 0.85—this is a 23% improvement over finetuning on FIB alone (PR AUC = 0.69). More importantly, the probability distributions of consistent vs. inconsistent summaries are better separated (right below), making the model more suitable for production. Relative to finetuning solely on FIB, at the same threshold of 0.8, we’ve increased recall from 0.02 to 0.50 (25x) and precision from 0.67 to 0.91 (+35%).
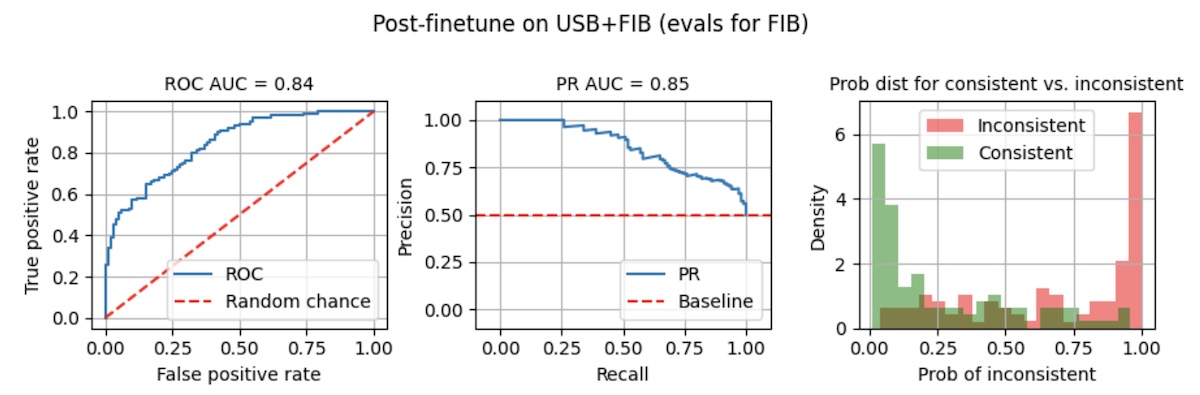 |
Or did it? Adding 10 epochs of FIB led to greatly improved performance
Considering that evals for the USB-finetuned (PR AUC = 0.60) and non-finetuned (PR AUC = 0.56) models weren’t that different, this improvement is unexpected. It suggests that, though finetuning on USB didn’t directly improve performance on FIB, the model did learn something useful that enabled the same 10 epochs of FIB-finetuning to achieve far better results. This also means that it may be tricky to directly assess the impact of data blending.
Takeaway: Pre-finetuning on Wikipedia summaries improved factual inconsistency classification in news summaries, even though the former is out-of-domain.
In other words, we bootstrapped on Wikipedia summaries to identify factually inconsistent news summaries. Thus, we may not need to collect as much finetuning data for our tasks if there are open-source, permissive-use datasets that are somewhat related. While this may be obvious for some, it bears repeating that transfer learning for language modeling can extend beyond pretraining to finetuning (also see InstructGPT and its predecessor).
(Also, it’ll likely work just as well if we blend both datasets and finetune via a single stage instead of finetuning in multiple stages on each dataset separately. That said, doing it in stages helped with understanding and visualizing the impact of each dataset.)
• • •
I hope you found this as exciting to read as it was for me to run these experiments. The code is available here. What interesting findings and tricks have you come across while finetuning your own models? Also, what other approaches work well for factual inconsistency detection? Please DM me or leave a comment below!
Eugene Yan
I build ML, RecSys, and LLM systems that serve customers at scale, and write about what I learn along the way. Join 7,500+ subscribers!
Hey friends, Recently, I've been wondering if I should migrate from my current web app stack (FastAPI, HTML, CSS, and some JavaScript) towards a modern web framework. I was particularly interested in FastHTML, Next.js, and Svelte. To learn more about these frameworks, I built the same web app using each of them. Here's what I learned, plus some thoughts on how coding assistances can and will influence developer habits and choices. I appreciate you receiving this, but if you want to stop,...
Hey friends, I've been thinking and experimenting a lot with how to apply, evaluate, and operate LLM-evaluators and have gone down the rabbit hole on papers and results. Here's a writeup on what I've learned, as well as my intuition on it. It's a very long piece (49 min read) and so I'm only sending you the intro section. It'll be easier to read the full thing on my site. I appreciate you receiving this, but if you want to stop, simply unsubscribe. 👉 Read in browser for best experience (web...
Hey friends, Just got back from the AI Engineer World's Fair and it was a blast! I had the opportunity to give the closing keynote, as well as host GitHub CEO Thomas Dohmke for a fireside chat. Along the same lines, I've been thinking about how to interview for ML/AI engineers and scientists, and got together with Jason to write about the technical and non-technical skills to look for, how to phone screen, run interview loops, and debrief, and some tips for interviewers and hiring managers....