I build ML, RecSys, and LLM systems that serve customers at scale, and write about what I learn along the way. Join 7,500+ subscribers!
Reflections on AI Engineer Summit 2023
Hey friends,
It's been a while since my last email. That's because I was busy preparing for my talk at the inaugural AI Engineer Summit in San Francisco. Here are the slides and transcript.
While there, I got the chance to chat with folks on the edge of building and deploying LLM products and learned a few interesting insights. For one, evals and cost are the biggest challenges in deployment, while guardrails and caching were less prioritized. Also, code assistants will likely become more ubiquitous while 2024 may be the year of multimodal, and a few more point. Here's a short write-up about it that I hope you'll find useful.
I appreciate you receiving this, but if you want to stop, simply unsubscribe.
• • •
👉 Read in browser for best experience (web version has extras & images) 👈
I recently attended the first-ever AI Engineer Summit in San Francisco. There, I gave a talk on building blocks for LLM systems and also got to chat with folks on the edge of building and deploying LLM products. Here are some key takeaways:
Evals and serving costs are the biggest challenges when deploying. This is based on the early results of Amplify Partners’ survey on AI Engineering. Out of over 800 responses so far, evals and serving costs came out tops as the biggest pain points in deployment. While it’s reassuring to know that I’m not the only one struggling with this, it also means I’ll have to invest in them instead of waiting to be a fast follower.
There is still no good way to do evals. The spectrum of eval techniques is wide, ranging from deterministic yet brittle assert statements to stochastic and expensive model grading via a 3P LLM, with little in between.
Asserts check the output of LLMs for expected words or numbers. Thus, while they’re deterministic, they’re also somewhat brittle. In the Eval Driven Development workshop, they built an eval for an agent checking a page on Amazon for the cheapest book. Their eval expected “6.78” but the model returned “$6.78”, thus failing the test case.
Another example is checking the tables used in generated SQL. I learned that LLMs, even the strong ones, sometimes ignore the list of tables provided and make up new tables in the generated SQL. A simple check is to assert that the tables in the generated SQL are limited to the list of tables provided.
But aren’t LLM outputs too open-ended to adopt an assert-based approach? Here’s Bryan Bischof (Head of AI at Hex) at a panel discussion: “If you’re not able to find a simple way to eval the responses, you’re probably not trying hard enough”. I’d agree.
An alternative to asserts is using an LLM to grade outputs. However, from folks who’ve been doing this for months (e.g., AutoGPT team), this quickly gets expensive at scale. To address this, they’ve resorted to caching responses (e.g., VCR.py). Thus, if we only update an isolated component in the system, we just need to eval that component and use the cached response for the rest of the system.
There’s one exception that’s relatively straightforward to eval: Code generation. We check if the code runs and produces the expected output. (This may explain the relative success of coding assistants.) Thus, perhaps code is a good medium for eval. Then, the challenge becomes formulating expected responses as code.
If we don’t have good automated evals, a useful mechanism is a periodic human eyeballing. Some LLM-based products do this weekly, on a sample of a few dozen queries, to get an intimate feel of how their product is improving or regressing week over week. This allowed them to quickly notice regressions with each model rollout and take corrective action.
Cost-effectiveness depends on the task. For complex tasks, LLMs are relatively cheap. For example, getting GPT-4 to write a data connector plugin would cost ~$10 and a few hours. In comparison, an average dev might take days or weeks. Counterintuitively, using LLMs to automate simple repetitive tasks, such as evals, is expensive. Thus, it makes better sense, at least for now, to use LLMs for complex work vs. basic, frequent tasks.
LLMs need to be backward compatible with existing systems. Just like ML was just a small part of a larger production system, LLMs will be too. We’ve learned this lesson before.
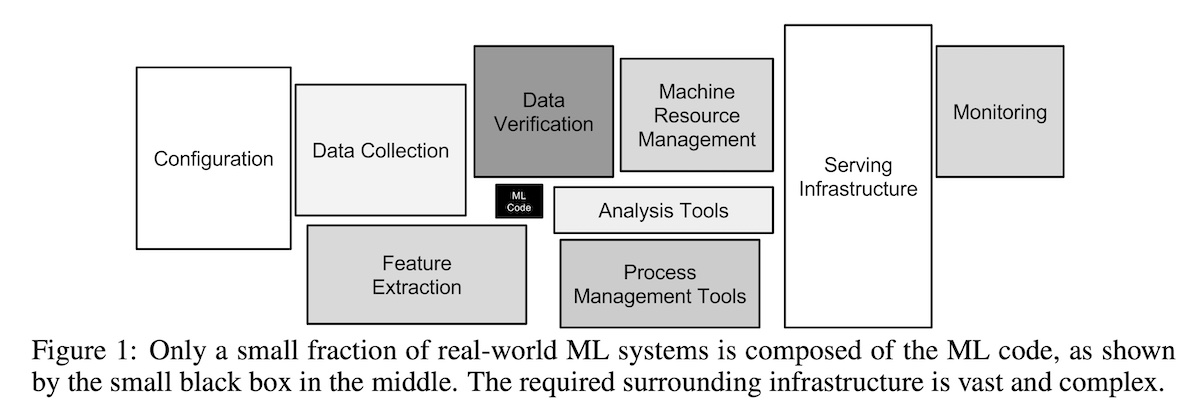 |
From Hidden Technical Debt in Machine Learning Systems (source)
Thus, we should think about integration sooner rather than later. JSON (OpenAI function calling) and XML (which Claude prefers) seem promising. Other tools include Guidance, Instructor, and TypeChat though the first of them doesn’t seem actively maintained.
Guardrails and moderation were less of a concern than expected. Few people I interacted with were concerned about them. I think this is because most use cases focus on LLM strengths, such as creativity and analyzing complex information (e.g., marketing copy, reading docs and writing code), and less on weaknesses like factual consistency. This suggests that it may be easier to build around use cases that have lesser moderation concerns, at least for now. However, use cases in industries that have low error and risk tolerance, such as finance and healthcare, remain tricky.
(Alternatively, it could be a blind-spot that devs are overlooking. Similarly, most folks I spoke to were finetuning on 3P LLM outputs despite it being against the terms of service.)
That said, in Shreya’s talk on Guardrails, it seems that the vision for Guardrails has expanded beyond the initial RAIL spec to include guards based on ML, DL classifiers, and self-reflection. She also spoke at length on the need to have guardrails on correctness which included embedding similarity, NLI, and self-reflection. Maybe this is based on chats with users and market demand?
There was surprisingly little discussion on caching to save costs. The only mention was at AutoGPT’s workshop, where they discussed using VCR.py to cache responses for evals. I wonder if it’s because the inputs to most LLM workloads are so unique that the benefits of caching are negligible, or if (semantic) caching is too unreliable to work in production.
Personally, I’m counting on caching to save ≥ 50% of LLM costs for large-scale systems. These systems, such as recsys, search, and customer support, likely have repetitive inputs and outputs that can benefit from caching. We just need to find smart ways to build caches for them—even something as naive as exact match can go a long way.
Retrieval-augmented generation (RAG) isn’t going away soon. There were three talks and an entire workshop dedicated to RAG databases and techniques. From the conversations and questions, it seems most teams are leaning heavily into RAG, at least for the short-to-medium term. Questions included how to combine metadata filters with vector search, how to effectively chunk/augment documents, how to eval, access control, etc.
Everyone can code now. With Replit making code assistance available to everyone and GitHub Copilot achieving ≥ 100M ARR, coding assistants are here to stay. It’s getting easier to start coding—education systems would jump on this opportunity to teach the next generation how to interact with machines and data.
2024 may be the year of multimodal. OpenAI demoed GPT-4V converting images to text, and then using that text to generate new images. Their talk included a slide on how text will likely be the “connective tissue” that binds multi-modality.
The world is still figuring out LLMs so it’s unclear if large multimodal models (LMMs) will take off yet. Nonetheless, text as the common medium makes sense—it’s flexible and can be used to compose structured data, code, logs, etc.
To finetune and self-host, or call APIs? Most folks I spoke to see finetuning and self-hosting small, specialized models as the way to improve performance and reduce cost. I’m of the same opinion. Nonetheless, some of us wondered if 3rd-partly LLMs will just improve over time like SSDs did, becoming so performant and cheap that it doesn’t make sense to use anything else. I’ll be watching closely how this plays out. 👀
SF engineers have incredible work ethic. I attended a Sunday 9 am workshop at an obscure co-working space: At 9 am the seats were half taken, and by 9.15 there weren’t enough chairs. For the Monday 8.45 workshops at the conference venue, by 8.20 it was half filled, and by 9.00 it was standing room only.
The questions they asked were amazing too. It was apparent that they already had a design doc in their heads and were asking questions about trade-offs, evals, cost, risk, etc. The energy was an order of magnitude above other conferences I’ve attended. These attendees were sprinting like rabbits running from wolves, not the wolves chasing what’s merely lunch. That said, this may not be a representative sample as the organized hand-picked 500 attendees over 10x as many applicants.
Overall, one of the best conferences I’ve attended in a while. Can’t wait for the next one.
• • •
Eugene Yan
I build ML, RecSys, and LLM systems that serve customers at scale, and write about what I learn along the way. Join 7,500+ subscribers!
Hey friends, I've been thinking and experimenting a lot with how to apply, evaluate, and operate LLM-evaluators and have gone down the rabbit hole on papers and results. Here's a writeup on what I've learned, as well as my intuition on it. It's a very long piece (49 min read) and so I'm only sending you the intro section. It'll be easier to read the full thing on my site. I appreciate you receiving this, but if you want to stop, simply unsubscribe. 👉 Read in browser for best experience (web...
Hey friends, Just got back from the AI Engineer World's Fair and it was a blast! I had the opportunity to give the closing keynote, as well as host GitHub CEO Thomas Dohmke for a fireside chat. Along the same lines, I've been thinking about how to interview for ML/AI engineers and scientists, and got together with Jason to write about the technical and non-technical skills to look for, how to phone screen, run interview loops, and debrief, and some tips for interviewers and hiring managers....
Hey friends, Recently a couple of friends and I got together to write about some challenges and hard-won lessons from a year of building with LLMs. One thing led to another and this is now published on O'Reilly in three sections: Tactics: Prompting, RAG, workflows, caching, when to finetune, evals, guardrails Ops: Looking at data, working with models, product and risk, building a team Strategy: "No GPUs before PMF", "the system not the model", how to iterate, cost We have a dedicated site...