I build ML, RecSys, and LLM systems that serve customers at scale, and write about what I learn along the way. Join 7,500+ subscribers!
Some Intuition on Attention and the Transformer
Hey friends,
A shorter post this week that answers some questions I've received on the concept of Attention and the Transformer architecture. Hope it clears up some doubts and provides useful intuition. Also, if you're looking for a list of open-LLMs (read: commercial license), you may be interested in this repo.
I appreciate you receiving this, but if you want to stop, simply unsubscribe.
• • •
👉 Read in browser for best experience (web version has extras & images) 👈
ChatGPT and other chatbots (e.g., Bard, Claude) have thrust LLMs into the mainstream. As a result, more and more people outside ML and NLP circles are trying to grasp the concept of attention and the Transformer model. Here, we’ll address some questions and try to provide intuition on the Transformer architecture. The intended audience is people who have read the paper and have a basic understanding of how attention works.
To keep it simple, I’ll mostly refer to “words” in a “sentence”. Nonetheless, attention can apply to any generic set of items in a sequence. For example, instead of words, we could have tokens, events, or products. And instead of a sentence, we could have a paragraph, in-session behavior, or purchase history.
What’s the big deal about attention?
Consider machine translation as an example. Before attention, most translation was done via an encoder-decoder network. The encoder encodes the input sentence (“I love you”) via a recurrent model and the decoder decodes it into another language (“我爱你”).
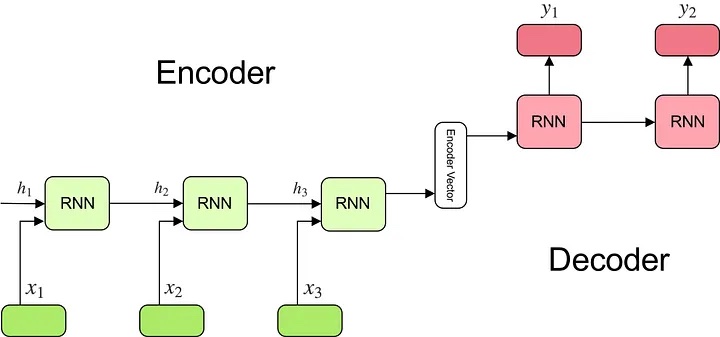 |
Encoding an input sentence into a fixed-size vector for the decoder (source)
Via this approach, the encoder had to cram the entire input into a fixed-size vector which is then passed to the decoder—this single vector had to convey everything about the input sentence! Naturally, this led to an informational bottleneck. With attention, we no longer have to encode input sentences into a single vector. Instead, we let the decoder attend to different words in the input sentence at each step of output generation. This increases the informational capacity, from a single fixed-size vector to the entire sentence (of vectors).
Furthermore, previous recurrent models had long paths between input and output words. If you had a 50-word sentence, the decoder had to recall information from 50 steps ago for the first word (and that data had to be squeezed into a single vector). As a result, recurrent models had difficulty dealing with long-range dependencies. Attention addressed this by letting each step of the decoder see the entire input sentence and decide what words to attend to. This cut down path length and made it consistent across all steps in the decoder.
Finally, prior language models leaned heavily on a recurrent approach: To encode a sentence, we start with the first word (w1) and process it to get the first hidden state (h1). Then, we input the second word (w2) with the previous hidden state (h1) to derive the next hidden state (h2). And so on. Unfortunately, this process was sequential and prevented parallelization. Attention tackled this by reading the entire sentence in one go and computing the representation of each word, based on the sentence, in parallel.
What are query, key, and value vectors?
Imagine yourself in a library. You have a specific question (query). Books on the shelves have titles on their spines (keys) that suggest their content. You compare your question to these titles to decide how relevant each book is, and how much attention to give each book. Then, you get the information (value) from the relevant books to answer your question.
In attention, the query refers to the word we’re computing attention for. In the case of an encoder, the query vector points to the current input word (aka context). For example, if the context was the first word in the input sentence, it would have a query vector q1.
The keys represent the words in the input sentence. The first word has key vector k1, the second word has vector k2, and so on. The key vectors help the model understand how each word relates to the context word. If the first word is the context, we compare the keys to q1.
Attention is how much weight the query word (e.g., q1) should give each word in the sentence (e.g., k1, k2, etc). This is computed via a dot product between the query vector and all the key vectors. (A dot product tells us how similar two vectors are.) If the dot product between a query-key pair is high, we pay more attention to it. These dot products then go through a softmax which makes the attention scores (across all keys) sum to 1.
Each word is also represented by a value which contains the information of that word. These value vectors are weighed by the attention scores that sum to 1. As a result, each context word is now represented by an attention-based weightage of all the words in the sentence, where the most relevant words have higher weight.
What does the encoder and decoder do?
The encoder takes a text input, such as a sentence, and returns a sequence of embeddings. These output embeddings can then be used for classification, translation, semantic similarity, etc. Self-attention enables the encoder to weigh the importance of each word and capture both short and long-range dependencies.
In contrast, the decoder takes inputs such as a start-of-sentence token and (optional) embeddings from the encoder, and returns probabilities to select the next word. Self-attention enables the decoder to focus on different parts of the output generated so far; cross-attention (aka encoder-decoder attention) helps it attend to the encoder’s output.
How does the decoder generate words?
The decoder outputs the probability of the next word (i.e., every possible word has an associated probability). Thus, we can generate the next word by greedily picking the word with the highest probability. Alternatively, we can apply beam search and keep the top n predictions, generate the word after next for each of these top n predictions, and select whichever combination had less error.
Why have multiple attention heads?
Multiple heads lets the model consider multiple words simultaneously. Because we use the softmax function in attention, it amplifies the highest value while squashing the lower ones. As a result, each head tends to focus on a single element.
Consider the sentence: “The chicken crossed the road carelessly”. The following words are relevant to “crossed” and should be attended to:
- The “chicken” is the subject doing the crossing.
- The “road” is the object being crossed.
- The crossing is done “carelessly”.
If we had a single attention head, we might only focus on a single word, either “chicken”, “road”, or “crossed”. Multiple heads let us attend to several words. It also provides redundancy, where if any single head fails, we have the other attention heads to rely on.
Why have multiple attention layers?
Multiple attention layers builds in redundancy (on top of having multiple attention heads). If we only had a single attention layer, that attention layer would have to do a flawless job—this design could be brittle and lead to suboptimal outcomes. We can address this via multiple attention layers, where each one uses the output of the previous layer with the safety net of skip connections. Thus, if any single attention layer messed up, the skip connections and downstream layers can mitigate the issue.
Stacking attention layers also broadens the model’s receptive field. The first attention layer produces context vectors by attending to interactions between pairs of words in the input sentence. Then, the second layer produces context vectors based on pairs of pairs, and so on. With more attention layers, the Transformer gains a wider perspective and can attend to multiple interaction levels within the input sentence.
Why have skip connections?
Because attention acts as a filter, it blocks most information from passing through. As a result, a small change to the inputs of the attention layer may not change the outputs, if the attention score is tiny or zero. This can lead to flat gradients or local optima.
Skip connections help dampen the impact of poor attention filtering. Even if an input’s attention weight is zero and the input is blocked, skip connections add a copy of that input to the output. This ensures that even small changes to the input can still have noticeable impact on the output. Furthermore, skip connections preserve the input sentence: There’s no guarantee that a context word will attend to itself in a transformer. Skip connections ensure this by taking the context word vector and adding it to the output.
• • •
Finally, here’s what Andrej Karpathy had to say about Transformers (and Attention).
References
- Attention Is All You Need
- The Illustrated Transformer
- Transformers From Scratch
- Transformers From Scratch (yeap, same title, not an error)
- Understanding the Attention Mechanism in Sequence Models
Eugene Yan
I build ML, RecSys, and LLM systems that serve customers at scale, and write about what I learn along the way. Join 7,500+ subscribers!
Hey friends, Just got back from the AI Engineer World's Fair and it was a blast! I had the opportunity to give the closing keynote, as well as host GitHub CEO Thomas Dohmke for a fireside chat. Along the same lines, I've been thinking about how to interview for ML/AI engineers and scientists, and got together with Jason to write about the technical and non-technical skills to look for, how to phone screen, run interview loops, and debrief, and some tips for interviewers and hiring managers....
Hey friends, Recently a couple of friends and I got together to write about some challenges and hard-won lessons from a year of building with LLMs. One thing led to another and this is now published on O'Reilly in three sections: Tactics: Prompting, RAG, workflows, caching, when to finetune, evals, guardrails Ops: Looking at data, working with models, product and risk, building a team Strategy: "No GPUs before PMF", "the system not the model", how to iterate, cost We have a dedicated site...
Hey friends, I've been helping teams with their prompts lately and was sad to see how they didn't have a good understanding of the basics, even as they reached for advanced techniques and complicated prompting tools. This spurred me to write this piece on the fundamentals of prompting. By mastering these, we should get 80 - 90% of they way to the optimal prompt. Aside: My friend Hamel Husain is organizing an LLM Conference + Finetuning Workshop: 11 talks by world-class practitioners like...