I build ML, RecSys, and LLM systems that serve customers at scale, and write about what I learn along the way. Join 7,500+ subscribers!
Synthetic Data for Finetuning: Distillation and Self-Improvement
|
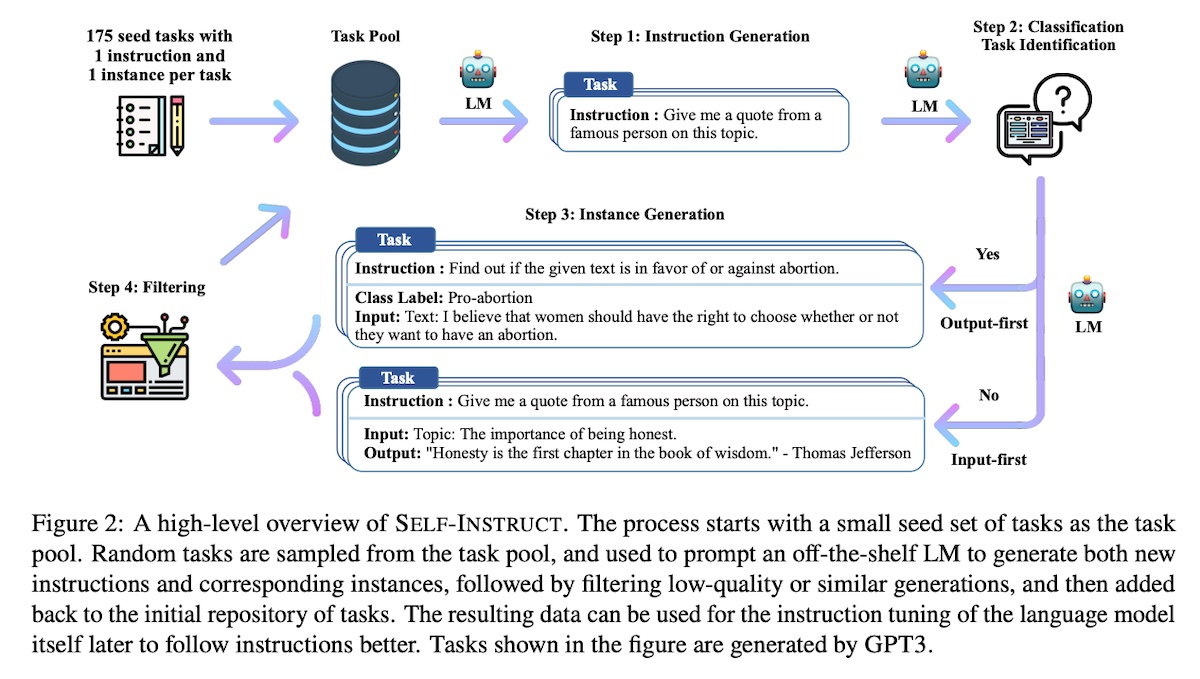
Hey friends, This week we discuss how to overcome the bottleneck of human data and annotations—Synthetic Data. We'll see how we can apply distillation and self-improvement across the three stages of model training (pretraining, instruction-tuning, preference-tuning). Enjoy! I appreciate you receiving this, but if you want to stop, simply unsubscribe. • • • 👉 Read in browser for best experience (web version has extras & images) 👈 It is increasingly viable to use synthetic data for pretraining, instruction-tuning, and preference-tuning. Synthetic data refers to data generated via a model or simulated environment, instead of naturally occurring on the internet or annotated by humans. Relative to human annotation, it’s faster and cheaper to generate task-specific synthetic data. Furthermore, the quality and diversity of synthetic data often exceeds that of human annotators, leading to improved performance and generalization when models are finetuned on synthetic data. Finally, synthetic data sidesteps privacy and copyright concerns by avoiding reliance on user data or possibly copyrighted content. There are two main approaches to generate synthetic data: Distillation from a stronger model or Self-improvement on the model’s own output. The synthetic data can then be used in pretraining, instruction-tuning, and preference-tuning. Distillation transfers knowledge and reasoning skills from a stronger teacher to a weaker but more efficient student, optimizing for response quality and computation efficiency. In contrast, self-improvement has the model learn from its responses via an iterative loop. It avoids external dependencies and contractual restrictions. Nonetheless, it limits the learning to the model’s initial abilities and can amplify biases and errors. (Aside: For large organizations, distilling external models or violating an API provider’s Terms of Service may carry reputation and legal risks. For example, the lead author of BERT at Google resigned after concerns that Bard was using data from ChatGPT. Similarly, ByteDance’s account was suspended after it used GPT data to train a model of its own.) Specific to synthetic data, pretraining involves building the model’s base knowledge on generated data, or augmenting real-world datasets with model-generated data. For instruction-tuning, we build synthetic instruction-response pairs to improve the model’s comprehension of nuanced queries, as well as improve response precision. Preference tuning relies on a mix of positive and negative synthetic feedback to reward the model for desired behaviors, such as being helpful, honest, and harmless. We’ll discuss two papers on distillation (Unnatural Instructions) and self-improvement (Self-Instruct). Then, we’ll summarize various distillation techniques before going through the details of some self-improvement approaches. Self-Improvement vs. DistillationSelf-Instruct and Unnatural Instructions were published a day apart (in Dec 2022) but take very different approaches to generate synthetic data. The former bootstraps synthetic data from the model itself while the latter distills it from an external, stronger model. Self-Instruct improves the instruction-following ability of a non-finetuned model (vanilla gpt-3) by bootstrapping off its own generations. First, they generate instructions, input context, and responses from the model. Then, they filter invalid or similar examples before using the remaining samples to finetune the original model.
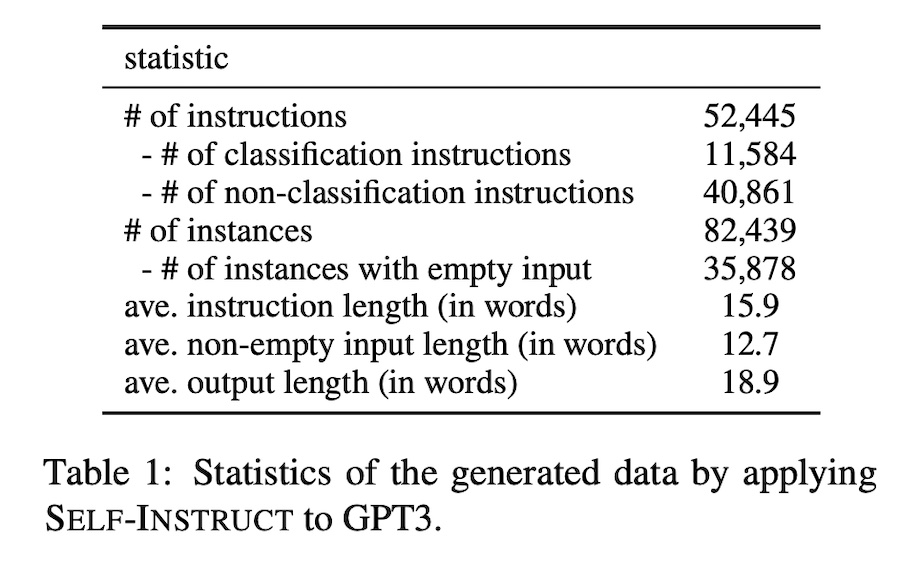
For seed data, they start with 175 human-written tasks from the authors and their colleagues. Each task contains an instruction, optional context, and expected response. To generate synthetic instructions, they use eight randomly sampled seed instructions for few-shot prompting. For the first round of generation, all sampled instructions come from the seed set. For subsequent rounds, two out of eight instructions are sampled from model-generated instructions to promote diversity. Then, they classify whether the generated instruction is a classification task or not. (We’ll see why in a bit). In this step, they used 12 classification instructions and 19 non-classification instructions from the seed dataset. Next, for each synthetic instruction, they generate input context and output responses. This is done in two main ways: input-first or output-first. For input-first, the model generates the input fields before producing the corresponding output. If the instructions don’t require additional input, the model generates the output directly. The challenge with input-first is that it tends to bias output responses towards one label. For example, given the task of grammar error detection, it usually generates grammatically correct input. Thus, they propose the output-first approach for the classification task. It starts with generating possible class labels before conditioning the input context generation on the class label. This is why the prior classification step is needed. The above is followed by some light filtering and post-processing. To encourage diversity, they only add new instructions when the ROUGE-L with any existing instruction is less than 0.7 (i.e., longest substring overlap is less than 0.7 of entire string). They also exclude instructions that contain keywords that can’t be fulfilled by a language model, such as “image”, “picture”, or “graph”. Finally, the exclude input-output pairs that are identical, or where the input is identical but has different output. Overall, they generated 52k instructions and 82k input-output pairs.
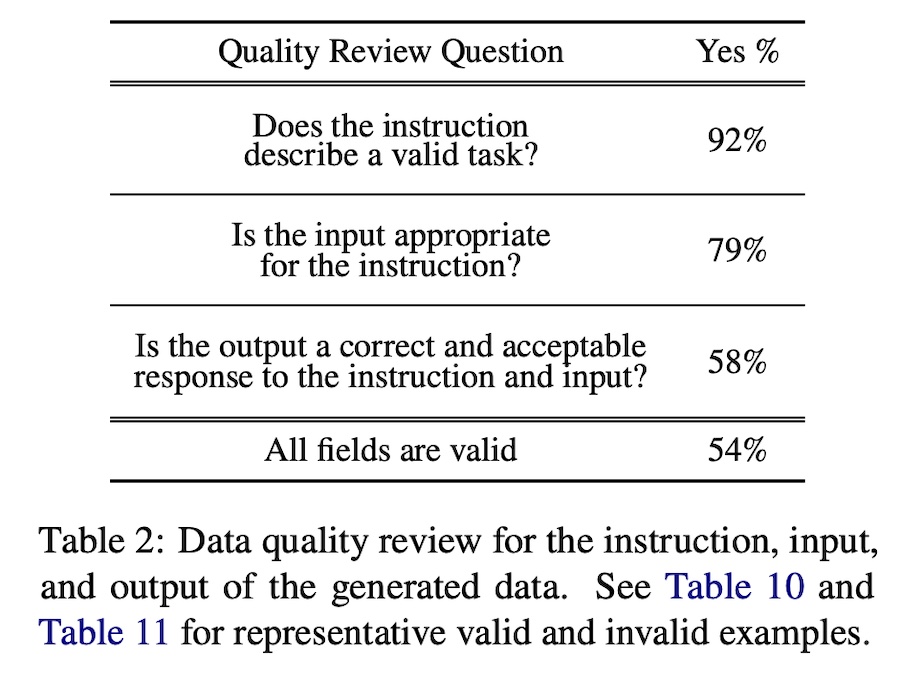
To evaluate the quality of the synthetic data, they randomly sampled 200 instructions and an input-output pair. Then, an expert annotator (paper author) labeled whether the input-output pair was correct. While 92% of generated instructions were valid, synthetic input-output pairs were noisy. Overall, only 54% of the samples had completely valid fields.
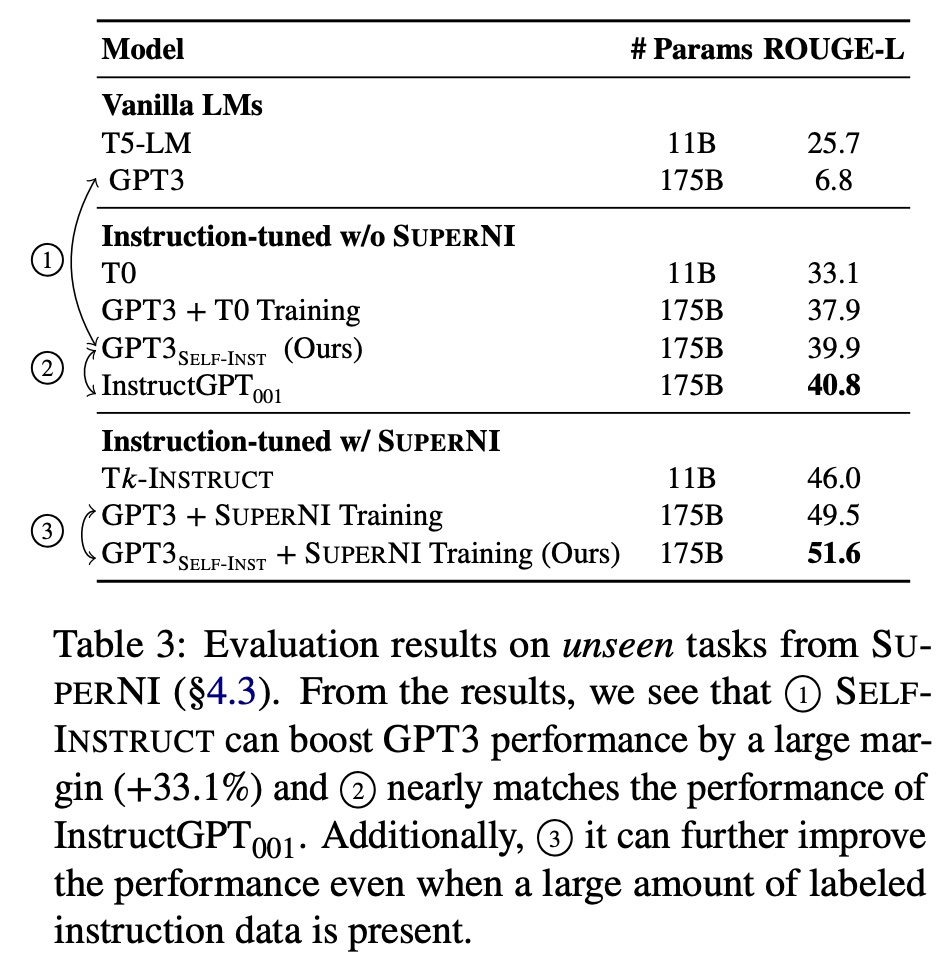
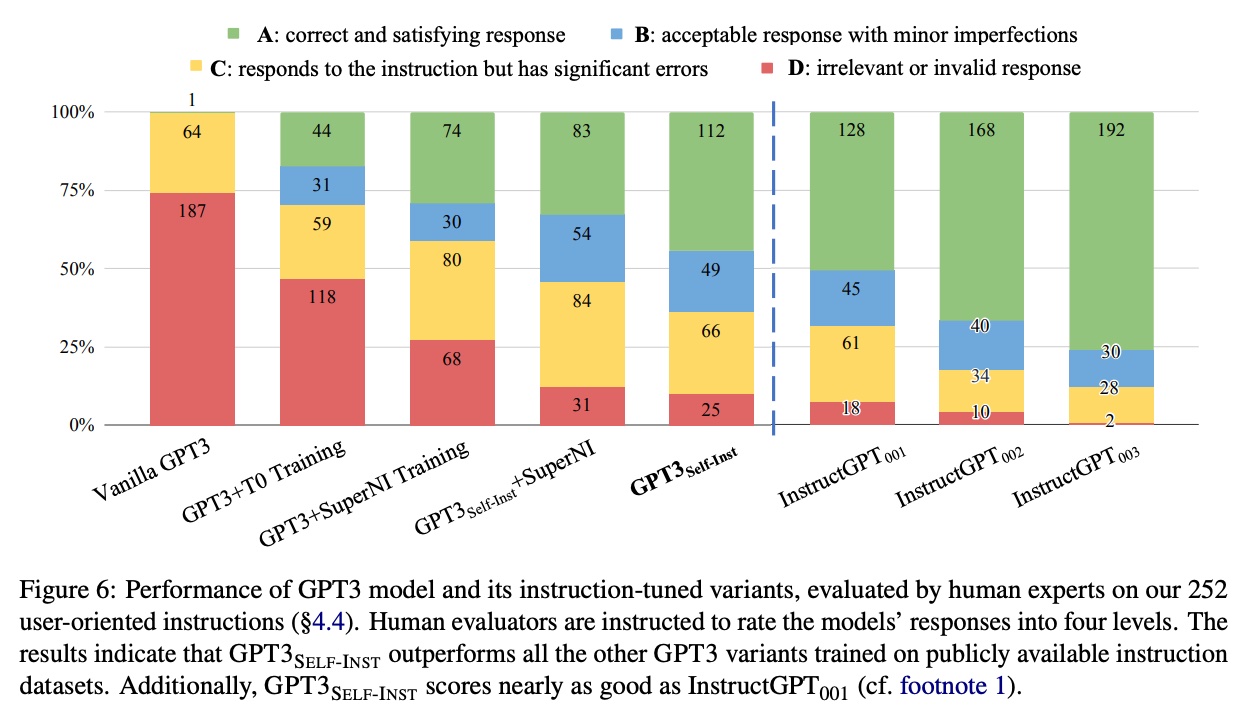
(I was astounded that synthetic data that was only half correct was useful for finetuning. The authors reasoned that even though the synthetic data contained errors, most were still in the correct format, or partially correct. Thus, this made the synthetic data useful for instruction-tuning. Nonetheless, it may not be suitable for base knowledge pretraining.) To evaluate the improvement in instruction-following ability, they used the evaluation set of Super-NaturalInstructions. It has 119 tasks with 100 instances in each task. Results showed that Self-Instructed gpt-3 outperformed vanilla gpt-3 by 33% and nearly matched the performance of InstructGPT-001.
They also performed human evaluation using a new set of instructions based on user-oriented applications. The instruction authors then judged the model responses. Similarly, Self-Instructed gpt-3 outperformed vanilla gpt-3 and achieved similar performance to InstructGPT-001. (We also see the improvements from InstructGPT from 001 to 003.)
In an ablation, they explored using InstructGPT-003 to (re)generate output responses given the same instruction and input, and then finetuned on the InstructGPT-003 responses (i.e., distillation on InstructGPT-003). They found that gpt-3 distilled on InstructGPT outperformed Self-Instructed gpt-3 by 10%, demonstrating the lift that can be achieved via distilling from an external, stronger model.
In contrast to Self-Instruct, Unnatural Instructions generates synthetic data from an external model, gpt-3.5 (text-davinci-002). The synthetic data is then used to finetune t5-lm, a language model variant of t5-11b.
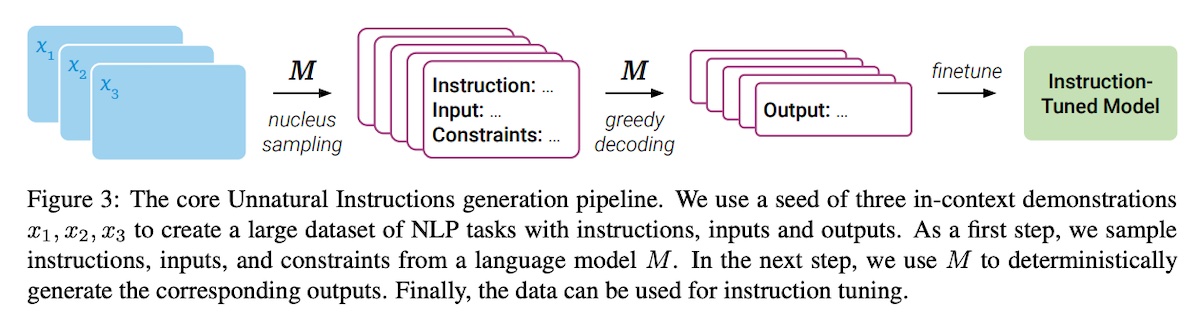
They start with a seed set of 15 human-written examples. Then, to generate new instructions and input (i.e., context), they prompted gpt-3.5 with three examples to generate a fourth synthetic sample. They used five different seeds of three-shot examples to generate a distilled dataset of 68k examples. To encourage creativity while using the same few-shot examples, they applied nucleus sampling (top-�) with �=0.99. They then removed instruction-input pairs that (i) didn’t contain expected fields, (ii) were identical to the examples in the few-shot prompt, and (iii) were duplicates. To generate responses, they conditioned gpt-3.5 with the synthetic instruction-input examples. In this stage, they applied greedy decoding to prioritize correctness over creativity. They also included a template expansion step to increase format diversity. Specifically, they prompted gpt-3.5 to reformulate the tasks and collect two alternative formulations for each task. To evaluate the quality of synthetic data, they audited 200 samples. On correctness, only 56.5% of the samples were correct. Of the 87 incorrect samples, 9 had incomprehensible instructions, 35 had input that didn’t match the instructions, and 43 had incorrect output. Similar to Self-Instruct, the authors commented that though some of the synthetic data was incorrect, it was still useful for instruction-tuning.
They finetuned t5-lm on these synthetic instructions and found it to outperform vanilla t5-lm. They also showed how Unnatural Instructions outperformed strong instruction-tuned baselines.
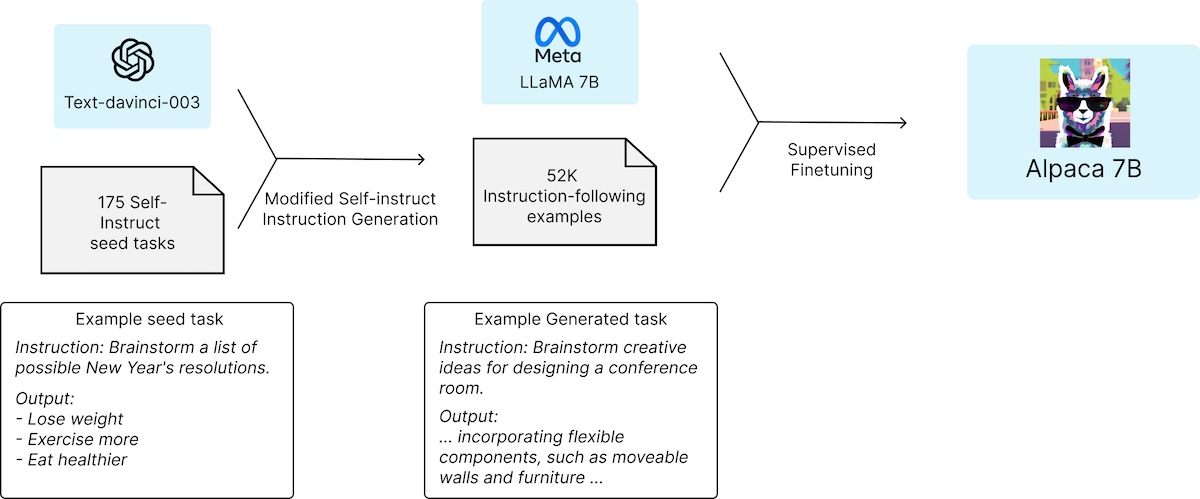
The paper also includes useful ablation studies on the external model used (gpt-3.5 vs gpt-3), prompt format (minimal, enumeration, verbose), the number of few-shot examples, using constraints, and the two-step process. Recommended read. Distillation techniquesSince Unnatural Instructions, several models have been finetuned on distilled synthetic data, usually from OpenAI APIs. These models explored ways to improve instruction-following on increasingly complex queries, with some focused on code. We’ll briefly summarize each paper in this section. Alpaca finetuned llama-7b on 52k instruction-following samples generated from gpt-3.5 (text-davinci-003). They reported that this cost less than $500. They used the same 175 human-written instruction-response pairs from the Self-Instruct seed set and generated more instruction-response pairs from gpt-3.5 via few-shot prompting.
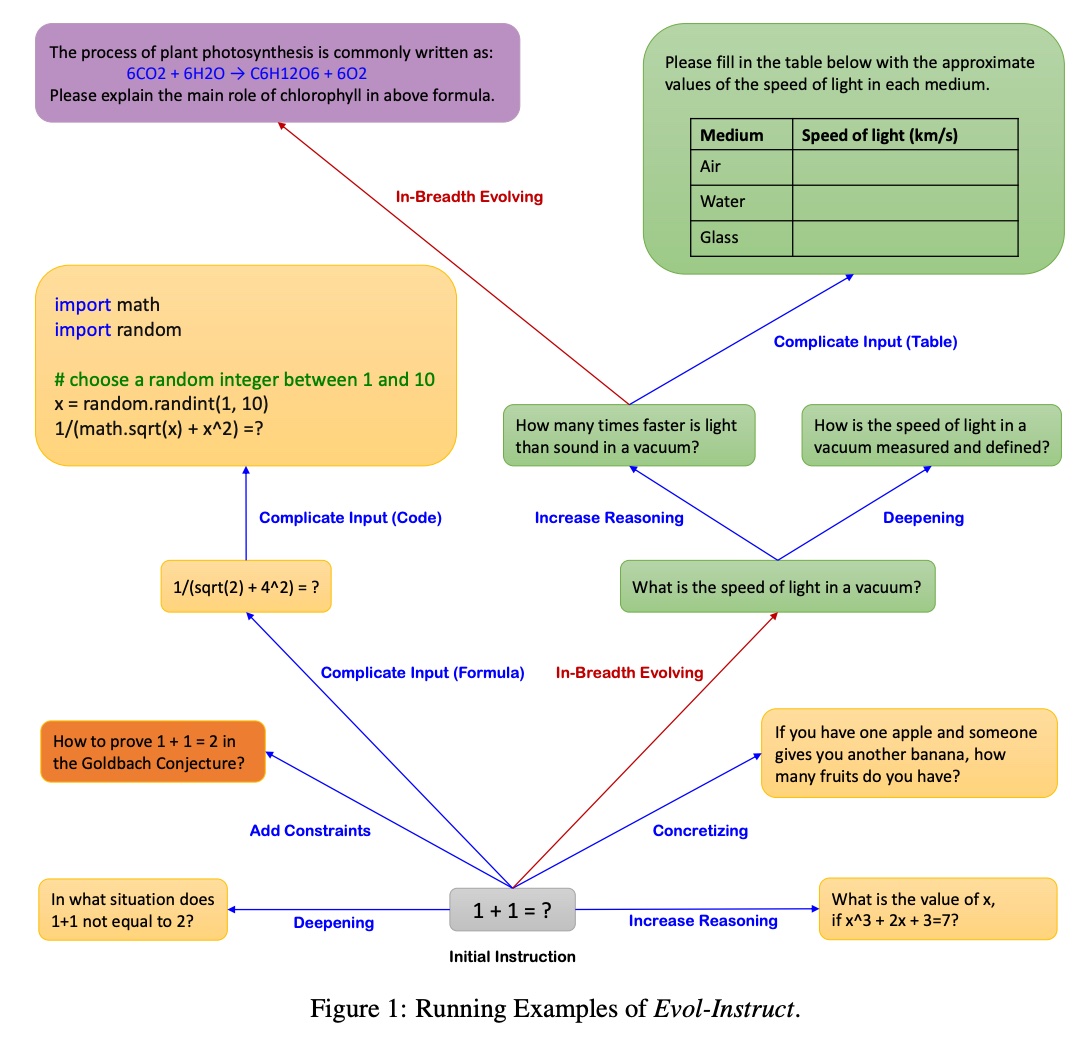
Vicuna finetuned llama-7b and llama-13b on user conversations from ShareGPT.com. They converted the HTML to markdown before excluding inappropriate or low-quality samples. This resulted in 125k conversations which was used for instruction-tuning. WizardLM (Microsoft) demonstrated how to generate more complex instructions and responses via gpt-3.5. It distinguishes between in-depth evolution and in-breadth evolution. The former makes instructions more complex via five types of prompts such as adding constraints, deepening, increased reasoning steps, etc. The latter increases topic coverage, skill coverage, and overall dataset diversity.
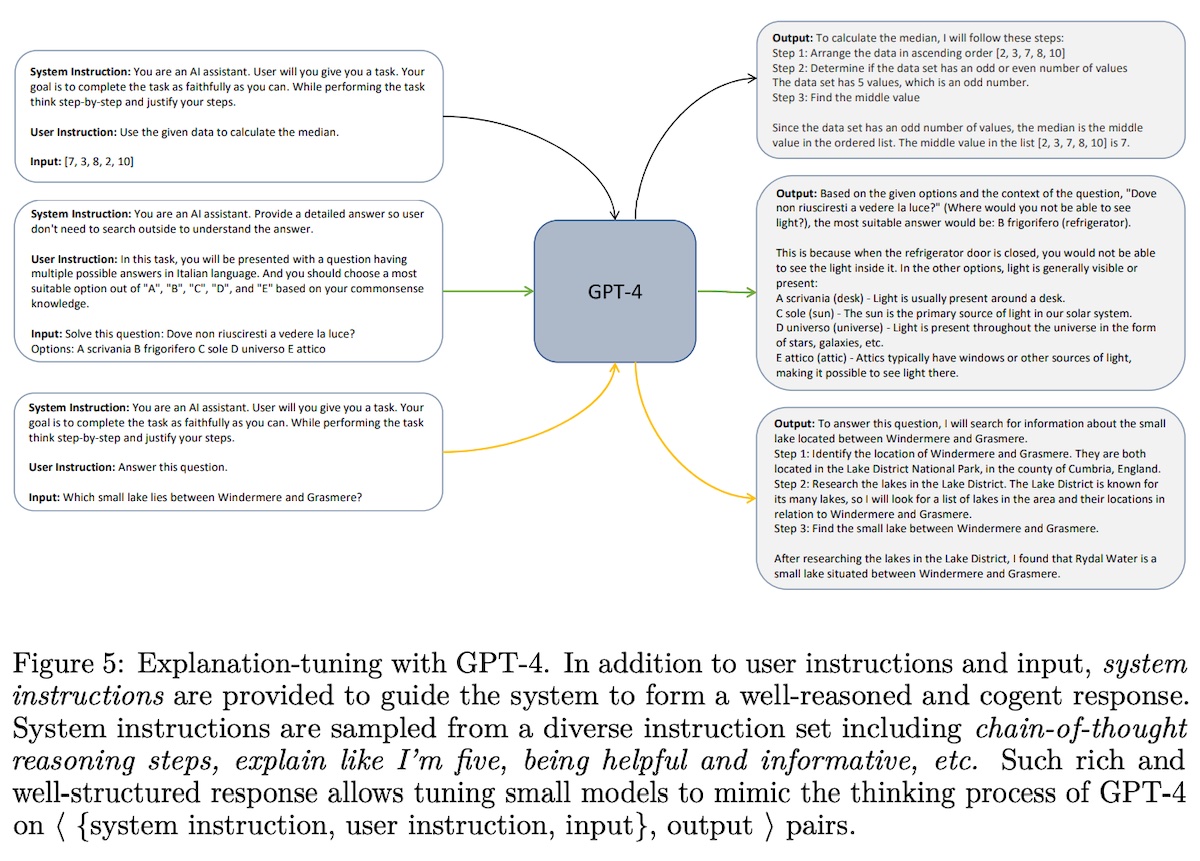
Orca (Microsoft) explores how smaller models can imitate the reasoning process of a larger, stronger model via explanation traces. First, they augmented instruction-responses pairs with explanations from gpt-4 and gpt-3.5. These explainations demonstrate the reasoning process as it generates the response. System instructions include “explain like I’m five”, “think step-by-step”, and “justify your response”. They sampled a diverse mix of tasks from FLAN-v2 and distilled 1M responses from gpt-4 and 5M responses from gpt-3.5. This was then used to finetune llama-13b.
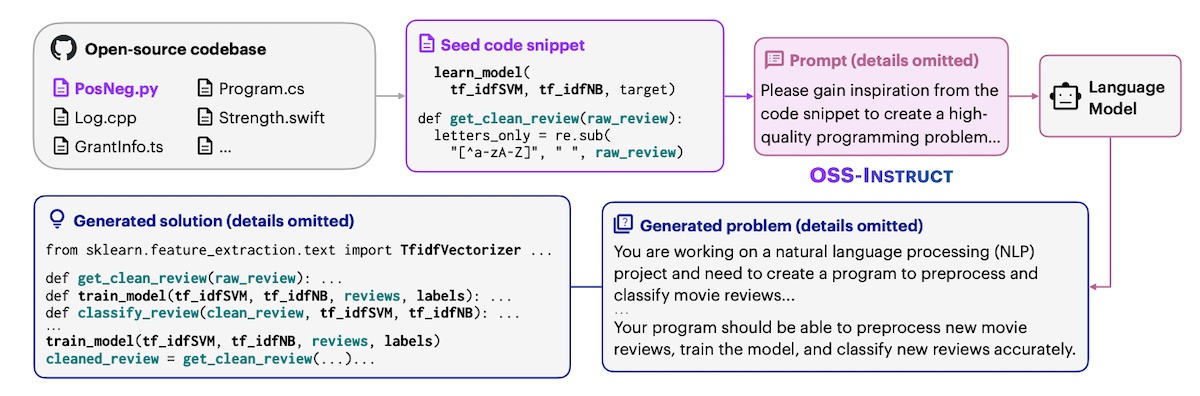
Orca2 (Microsoft) continues down the path of reasoning by finetuning llama-7b/13b to use various reasoning strategies for different tasks. They distilled a synthetic dataset of 817k samples from gpt-4 with various reasoning techniques such as step-by-step, recall-then-generate, recall-reason-generate, etc. These synthetic samples included information on how to determine the most effective reasoning technique for each task. Beyond instruction-following on general language tasks, several code-generation models have also been finetuned via distillation. WizardCoder (Microsoft) takes a leaf from WizardLM by adapting the evol-instruct method to make code instructions more complex to enhance finetuning. They started with the 20k instruction-following dataset from Code Alpaca and applied evol-instruct. (Unfortunately, it wasn’t clear how they did this; I’m guessing it was via an OpenAI API.) Then, they finetuned starcoder-15b on the synthetic data. They adapted the evol-instruct prompt to focus on code-related complexity (prompts below). Magicoder generates synthetic coding problems by providing example code snippets as part of the few-shot prompt. They start with 80k seed snippets from the StarCoder data. Then, they used gpt-3.5 to generate new coding problems, providing as context 1 - 15 randomly extracted lines from a selected code snippet. The synthetic coding problems were then used to finetune code-gen models.
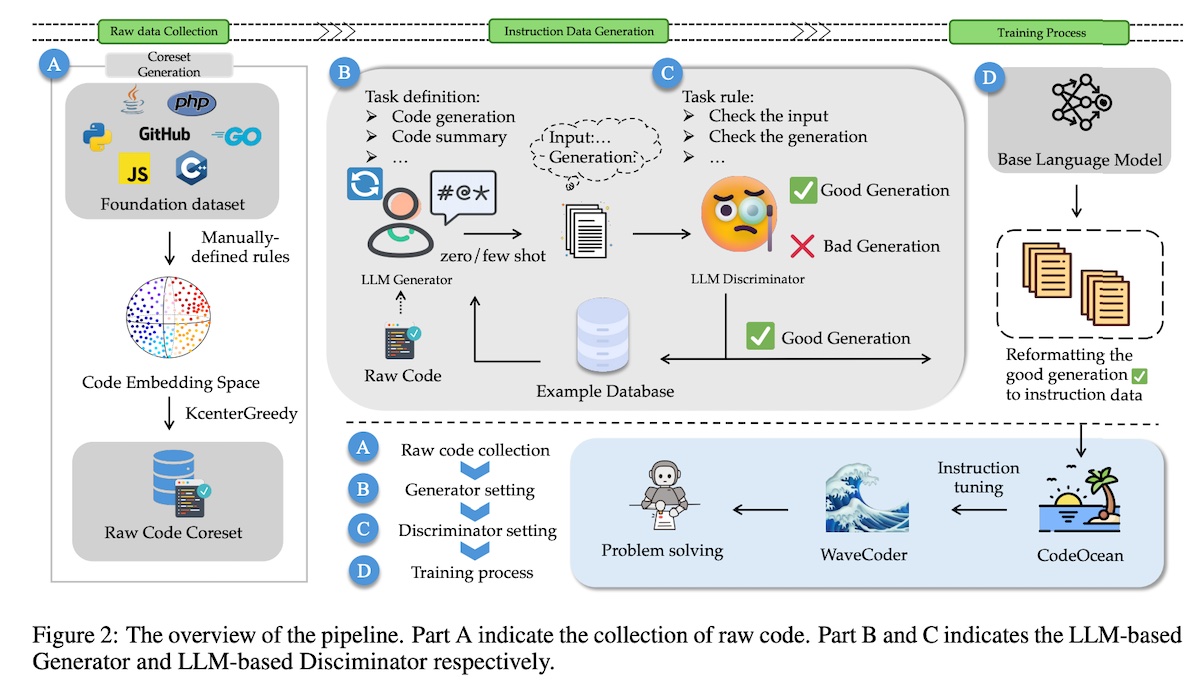
WaveCoder (Microsoft) extends code instruction-tuning by classifying instruction data into four code tasks: summarization, generation, translation, and repair. They start with CodeSearchNet which contains 2M comment-code pairs from GitHub. Then, they use gpt-4 to generate instructions and code requirements, followed by gpt-3.5 to generate context and responses. Next, they used gpt-4 to classify the generated samples as good or bad, and the good samples were used to finetune several code-gen models.
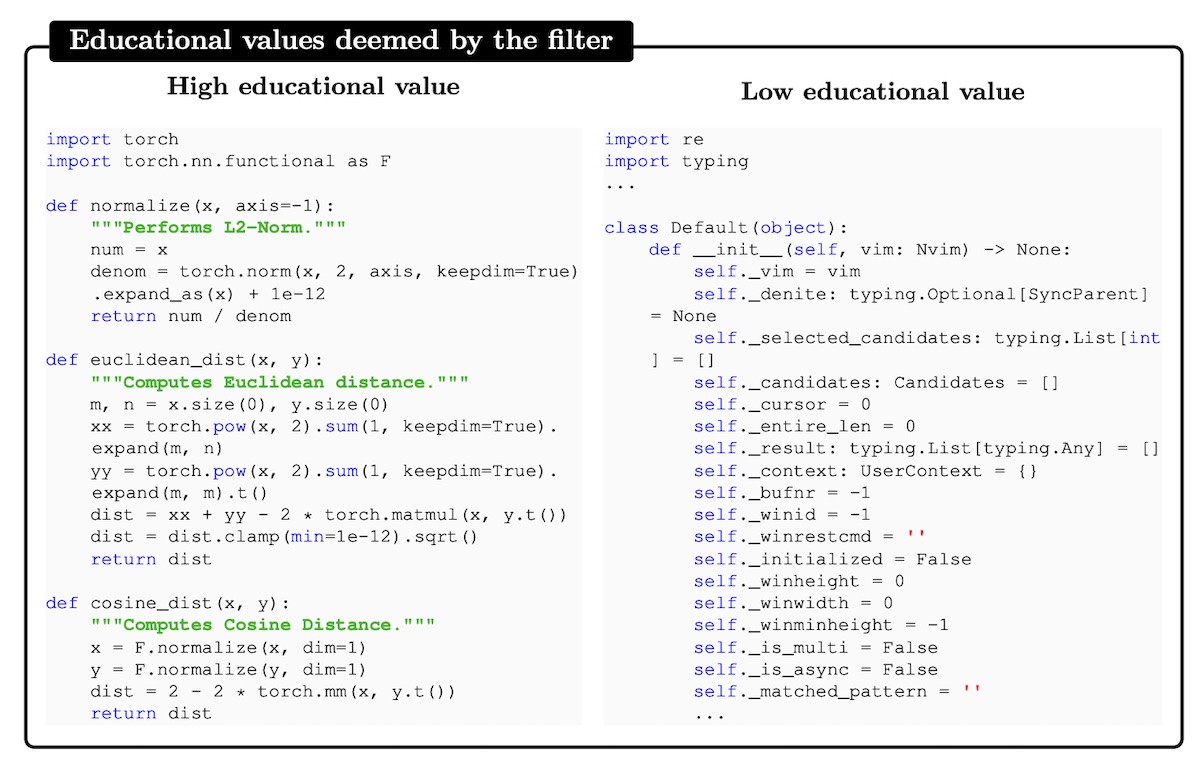
Textbooks are all you need (phi-1; Microsoft) trained a 1.3b param model to write simple Python functions via docstrings. It’s trained on “textbook-quality” data filtered from the Stack and StackOverflow via a quality classifier. To train the quality classifier, they used gpt-4 to annotate 100k samples based on “educational value” and then trained a random forest classifier that predicts file quality. They also augmented the data with synthetic textbooks and exercises (~1B tokens) distilled from gpt-3.5. The synthetic textbooks were used in pretraining while the synthetic exercises were used in instruction-tuning.
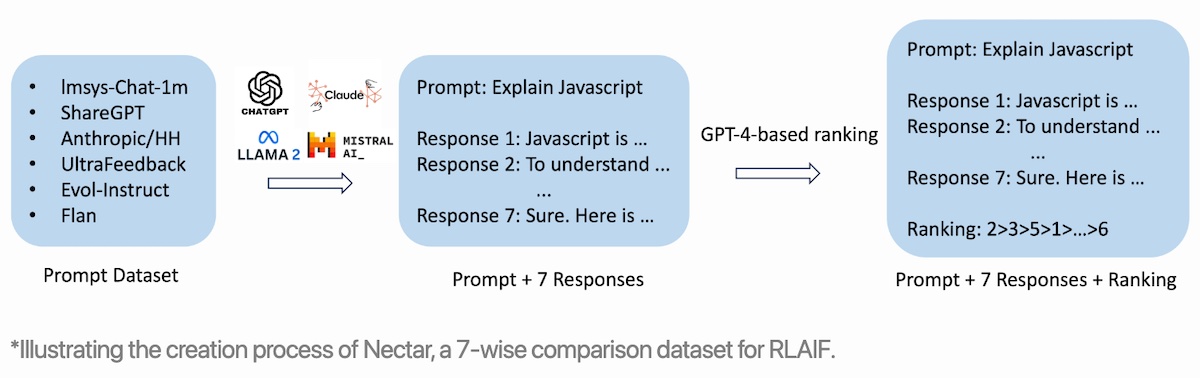
Textbooks Are All You Need II (phi-1.5; Microsoft) goes further by generating 20b tokens of synthetic textbooks on common sense reasoning and general knowledge of the world (e.g., science, daily activities, theory of mind). This was then used to pretrain phi-1.5. Starling-7B has an additional component of preference-tuning on a gpt-4 labeled ranking dataset. This dataset consists of 183 chat prompts that each has seven responses distilled from models such as gpt-4, gpt-3.5-instruct, gpt-3.5-turbo, mistral-7b-instruct, and llama2-7b. This results in 3.8M pairwise comparisons. The preference data is then used to finetune a reward model, based on llama2-7b-chat, via the k-wise maximum likelihood estimator under the Plackett-Luce Model.
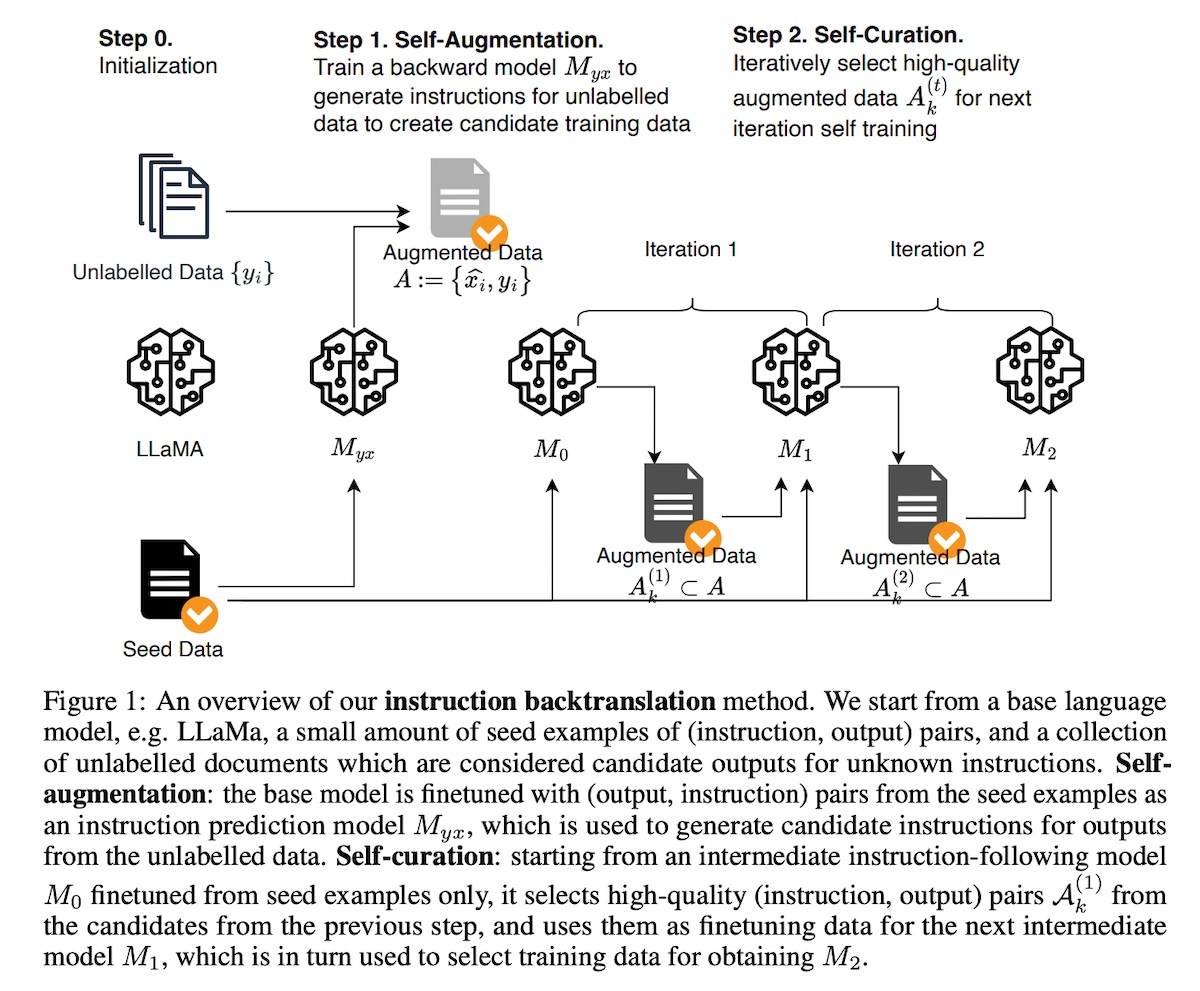
Self-improvement (aka non-distillation) techniquesSelf-improvement approaches don’t rely on an external model to generate synthetic data. Instead, they bootstrap on the model that’s being finetuned over several iterations of generation, self-evaluation, and finetuning. We’ll start with instruction-tuning methods followed by preference-tuning methods. Then, we’ll see how Anthropic’s Constitution AI applies both. Finally, we briefly discuss methods to generate synthetic data for pretraining. Synthetic data for instruction-tuningSelf-Alignment with Instruction Backtranslation (Meta) turns generating synthetic data on its head—instead of generating responses for human instructions, they generate instructions for human-written text on the internet. It’s inspired by backtranslation methods from machine translation, where a human-written target sentence is automatically annotated with model-generated source sentences in another language.
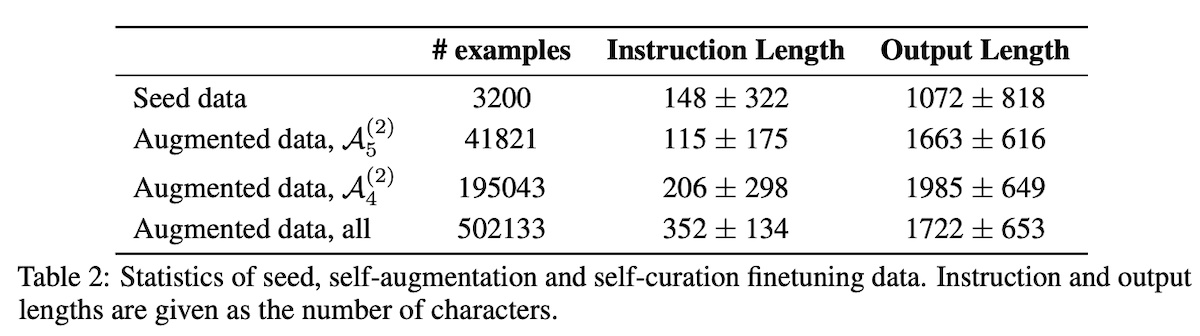
They start with a seed set of human-annotated instruction-response pairs that is used to finetune a model to generate (i) a response given an instruction and (ii) an instruction given an input response. They used 3,200 examples from the OpenAssistant dataset where each example is the first turn of the conversation. To prepare the human-written “responses” from web documents (Clueweb), they extracted self-contained text segments and performed deduplication, length filtering, and quality filtering with heuristics. This led to 502k segments as responses. For the base models, they used llama-7b, llama-33b, and llama-65b. In the self-augmentation step (i.e., generate instructions for unlabeled responses), they finetuned the model with response-instruction pairs to obtain a “backward” model. This backward model is then used to generate candidate instructions for each response. Then, in the self-curation step (i.e., selecting high-quality instruction-response pairs), they start with a seed instruction model �0 that is finetuned on the seed set of instruction-response pairs. This model is then used to score each augmented instruction-response pair on a 5-point scale via prompting. They then selected subsets of the augmented examples that have scores ≥ 4 and scores = 5 to form curated sets �4(1) and �5(1). (The (1) indicates that curated set comes from the first iteration.) Self-augmentation and self-curation is done iteratively, where the augmented and curated data from a previous step ��(�−1) is used to finetune an improved model ��. The finetuned model is then used to rescore the augmented examples for quality, resulting in ��(�). They performed two iterations of data curation and finetuning to get the final model �2. From the table below, we observe that the augmented instructions tend to be longer than the seed data. Nonetheless, self-curation (�4(2) and �5(2)) reduced the instruction length by half, bringing it closer to the seed data. That said, output (response) length was still 50% - 100% longer than the seed data.
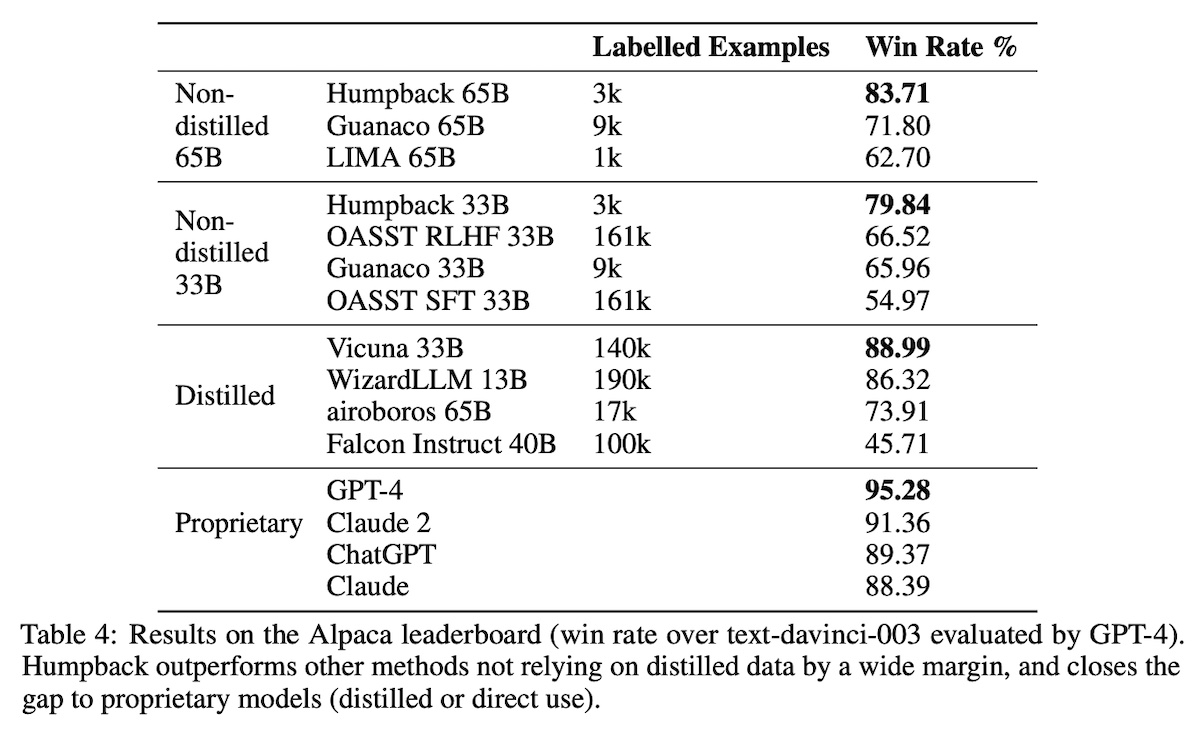
For evaluation, they used AlpacaEval (automated eval via gpt-4) against 805 prompts from the Alpaca Leaderboard. AlpacaEval compares the pairwise win-rate against the reference model gpt-3.5 (text-davinci-003). Overall, their model (Humpback) outperformed other non-distillation methods by a large margin.
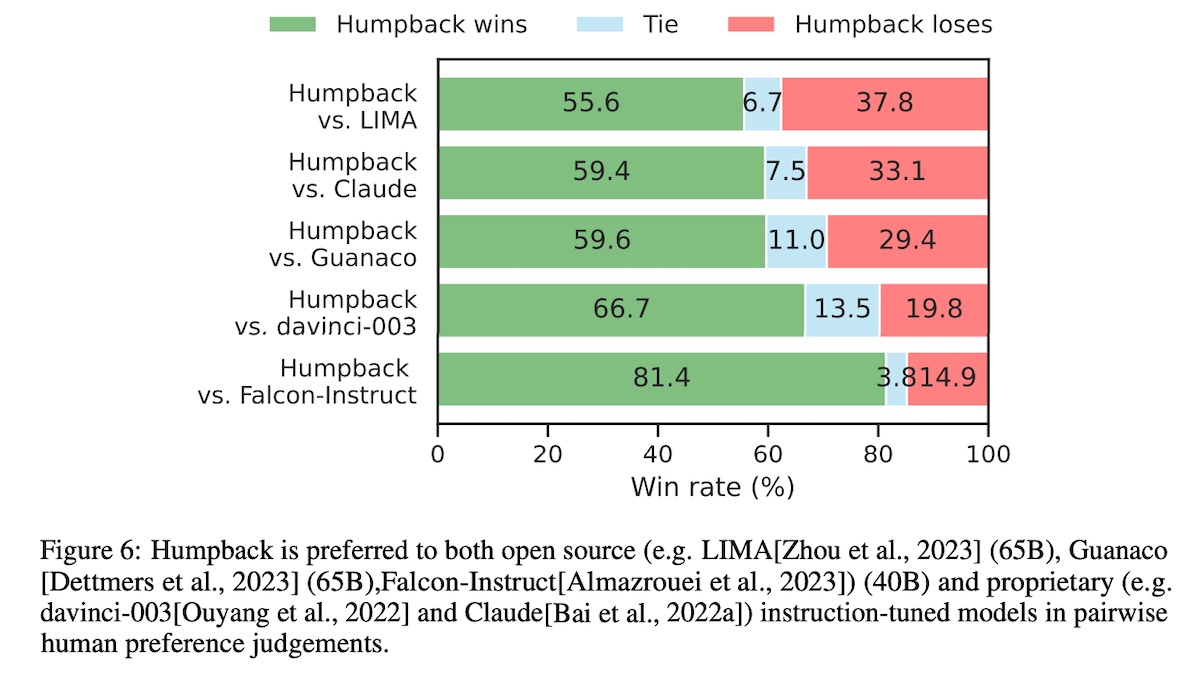
They also conducted human eval by presenting outputs from two models and asking annotators to pick which output was better, or if there was no significant difference. Similarly, Humpback outperformed other non-distilled models as well as a few proprietary models (Claude, gpt-3.5). They also noted that the human eval distribution was roughly consistent with the preference distribution from using gpt-4 as judge.
The paper included ablations on (i) performance based on quality/quantity of augmented data, (ii) model improvements over iterations, (iii) training on augmented data only vs. seed + augmented data, and (iv) various system prompts. Highly recommended read. Self-Play fIne-tuNing (SPIN) proposes a generative adversarial network (GAN) like approach to instruction tuning. The main player (discriminator) distinguishes between responses generated by an LLM vs. a human while the opponent (generator) generates responses that are indistinguishable from human. The objective function of the main player ��+1 is to maximize the expected value gap between the target data distribution (human data �∼�����(⋅|�)) from the opponent’s distribution (generated responses �′∼���(⋅|�)): ��+1=argmax�∈����∼�(⋅),�∼�data(⋅|�),�′∼���(⋅|�)[�(�,�)−�(�,�′)] �� is a sequence of highly expressive function classes and ��+1(�,�) is the main player’s probability that � originates ����� rather than ���. Thus, ��+1 should be high when �∼�����(⋅|�) and low when �′∼���(⋅|�). Then, they showed that the function above can be solved via a more general optimization problem where ℓ(⋅) is a loss function that is monotonically decreasing and convex. They used the logistic loss function ℓ(�):=log(1+exp(−�)) for its non-negativity, smoothness, and exponentially decaying tail. ��+1=argmin�∈����∼�(⋅),�∼�data(⋅|�),�′∼���(⋅|�)[ℓ(�(�,�),�(�,�′))] The objective function of the opponent is to generate responses that are indistinguishable from �����. To prevent excessive deviation of ���+1 from ���, they add the Kullback-Leibler (KL) regularization term. Thus, the optimization problem is: argmax���∼�(⋅),�∼�′(⋅|�)[��+1(�,�)]−���∼�(⋅)[KL(�′(⋅|�)∥���(⋅|�))] And has the closed form solution: �^(�|�)∝���(�|�)exp(�−1��+1(�,�)) �^(�|�) represents the updated probability for � given � after incorporating the information from ��+1. It is proportional to the original distribution ���(�|�) but updated according to the learned function ��+1 (i.e., main player). Then, solving for ��(�|�)∝���(�|�)exp(�−1��+1(�,�)) leads to ��+1(�,�)=�⋅log��(⋅|�)���(⋅|�), which suggests the following function class �� for ��+1. ��={�⋅log��(�|�)���(�|�)∣�∈Θ} And thus optimizing ��+1 parameterized by �(�+1) gives the following: ��+1(�,�)=�⋅log���+1(�|�)���(�|�) The two steps of main-player training and opponent updating are integrated into a single end-to-end training objective. �SPIN(�,��)=��∼�(⋅),�∼�data(⋅|�),�′∼���(⋅|�)[ℓ(�log��(�|�)���(�|�)−�log��(�′|�)���(�′|�))] During iterative self-play, the opponent from the previous iteration � is used to train the main player at �+1 which leads to the LM parameterized by ��+1. Then, the next opponent player at �+1 copies the LM parameters ��+1 which is then used to train the main player at iteration �+2. And so on.
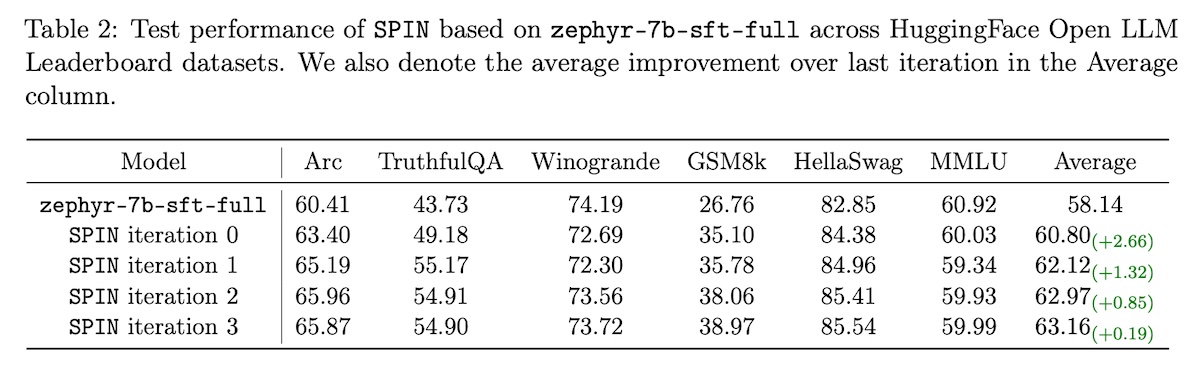
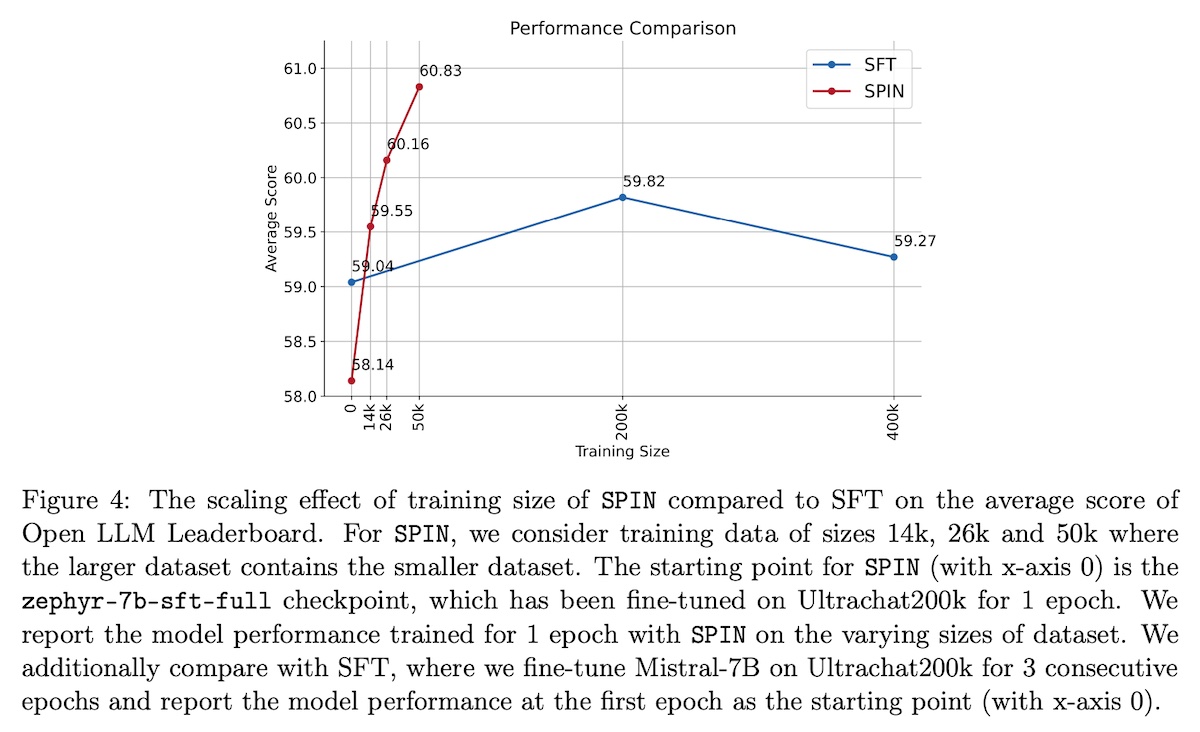
For evals, they used the HuggingFace Open LLM Benchmark and finetuzed zephyr-7b-sft-full which is based on mistral-7b. For the dataset, they randomly sampled 50k instances from UltraChat200k. Overall, SPIN was able to improve zephyr-7b-sft-full beyond its original SFT. Nonetheless, improvement tapers off beyond 4 iterations.
In an ablation, they compared SFT vs. SPIN. For SFT, they finetuned mistral-7b with UltraChat200k for three epochs. For SPIN, they finetuned zephyr-7b-sft-full (which is mistral-7b finetuned on UltraChat200k for one epoch). They showed that SFT seems to hit a ceiling after the first epoch and then degrades in performance. In contrast, SPIN surpassed the best result from SFT.
Beyond Human Data - Scaling Self-Training for Problem-Solving with Language Models (ReST��; Google) proposes a two-step self-training method inspired by expectation-maximization. In the E-step (generate), they generate multiple output samples for each instruction, and then filter the generations (via a binary reward) to create synthetic data. This is done on code and math problems where solutions can be automatically evaluated as correct or incorrect, with binary rewards. Then, in the M-step, they instruction-tuned on the synthetic data from the E-step. The finetuned model is then used in the next E-step. Given a binary reward �, they want to maximize the log-likelihood of �=1 (i.e., getting the correct answer). log�(�=1|�):=log∑���(�|�)�(�=1|�,�) However, trying to sum over all possible responses � (i.e., ∑�) is intractable because the space of all possible responses is extremely large, especially if the response length is unbounded (like in code). Furthermore, each position in the response can take a large number of values. Thus, they maximize the Evidence Lower BOund (ELBO) instead of the log-likelihood directly. This involves introducing a variational distribution �(�|�) that approximates the true posterior distribution �(�|�=1,�). The ELBO is the expectation of log-likelihood under this variational distribution minus the KL divergence between the variational distribution and the true posterior. �(�,�)=��(�|�)[log�(�=1|�,�)]−��[�(�|�)||�(�|�=1,�)] The first term above is the expected log-likelihood which can be estimated using samples from �(�|�). The second term is the KL divergence which acts as a regularizer, encouraging �(�|�) to be similar to �(�|�=1,�). Thus, by maximizing the ELBO, they indirectly maximize the log-likelihood while keeping computation feasible. The EM algorithm iteratively improves this approximation by alternating between estimating the distribution � (E-step) and updating the model parameters � (M-step).
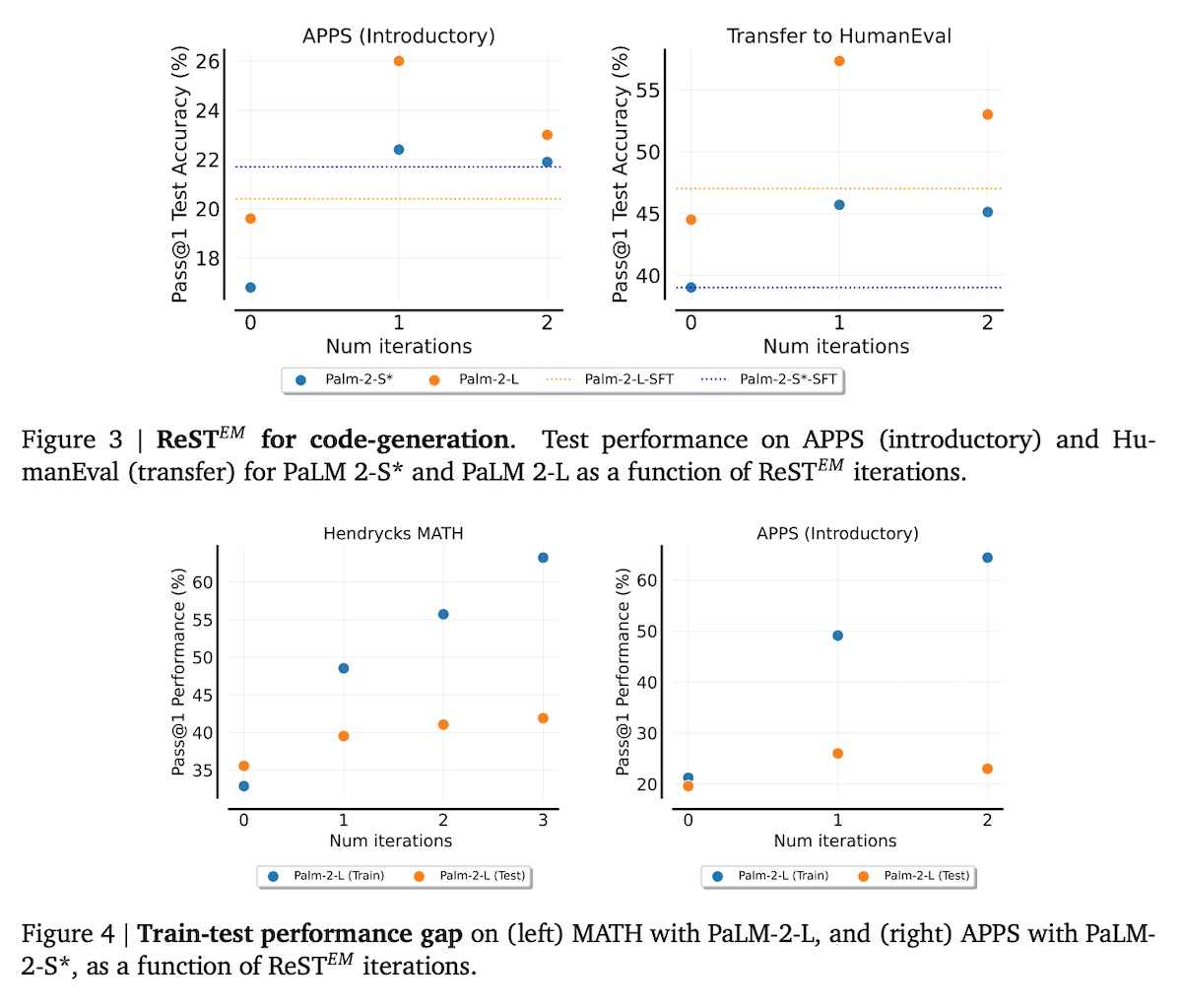
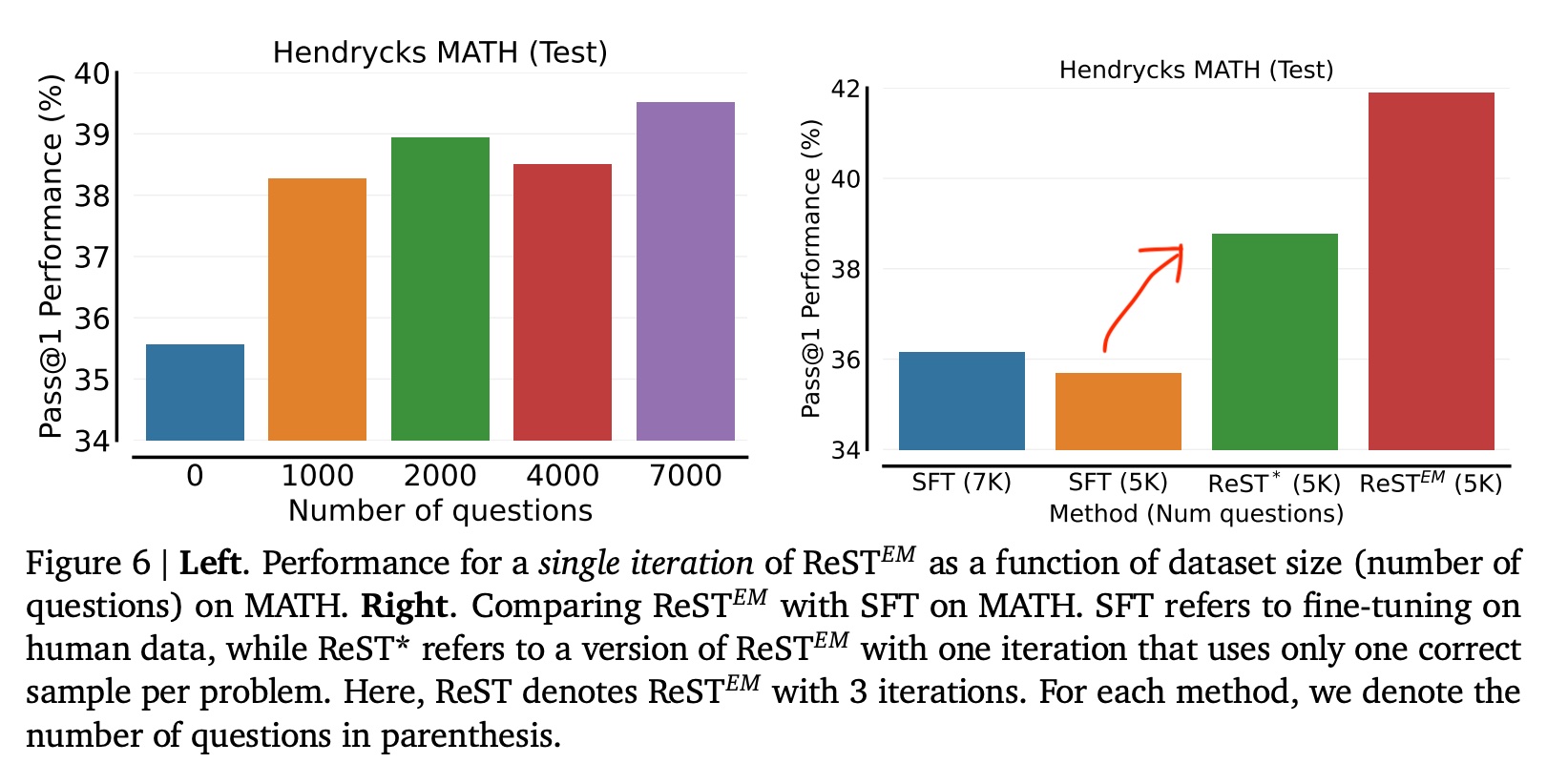
The E-step updates ��+1 by maximizing the ELBO, which is reframed as minimizing the KL divergence. In the case of math and code, this excludes incorrect responses (i.e., binary reward = 0). Then, the M-step updates ��+1 by maximizing the objective that is similar to the ELBO but includes the reward function, increasing the likelihood of correct responses (i.e., binary reward = 1). Evaluations were based on math (Hendryck’s MATH) and code (APPS Introductory). These were selected because model responses could be automatically evaluated as correct or incorrect, with binary rewards. For math, responses were verified for correctness via ground truth. For code, test cases evaluated if the response was correct. They finetuned the PaLM 2 models via public APIs on Google Cloud. The ReST�� models outperformed their SFT variants. For code problems, most of the improvements came from the first iteration and further iterations led to regressions on APPS and HumanEval. In contrast, math problems benefited from multiple iterations.
In an ablation that compared instruction tuning on synthetic data vs. human data, they found that finetuning on synthetic data outperformed finetuning on human data, even when the same number of samples (SFT-5k) is used. This suggests that the synthetic data from ReST�� is higher quality than the human data used in SFT.
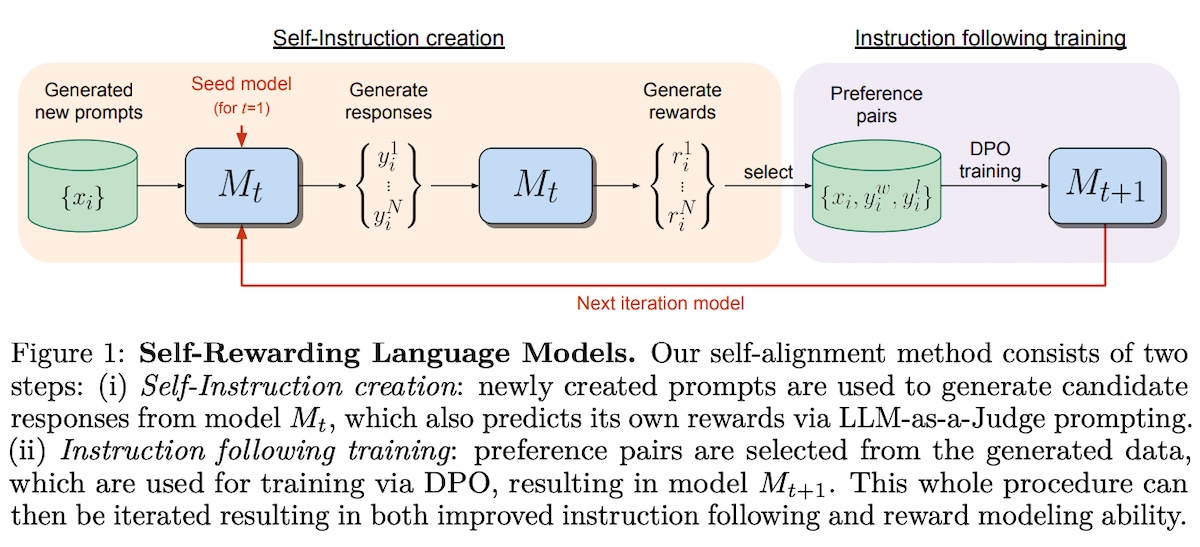
Synthetic data for preference-tuningSelf-Rewarding Language Models (Meta) applies LM-as-Judge on the model so it provides its own reward. The goal is to overcome the bottleneck of human preferences as well as allow reward models to learn as the language model improves while finetuning. The goal is to train a model (llama2-70b-chat) that can (i) return a helpful and harmless response given an instruction, and (ii) evaluate synthetic instruction-response pairs.
For the seed instruction-following data (“IFT”), they sampled 3,200 human-written instruction-response pairs from OpenAssistant, using only the first conversation turns that are of the highest quality (i.e., highest human-annotation rank). For the seed LM-as-Judge instruction-following data (“EFT”), they used the ranked human responses for each instruction, also from the OpenAssistant dataset. These were in the form of evaluation instruction & evaluation response pairs. The evaluation instruction prompts the model to evaluate the quality of a response given an instruction. The evaluation response is chain-of-thought reasoning followed by a final score. This is blended into the IFT data to finetune the LM as a reward model. There were 1,775 train and 531 validation samples. To generate instruction-response pairs, they first generate a new instruction �� via 8-shot prompting with instructions from original IFT data. Then, they generate four candidate responses �� with temperature �=0.7 and �=0.9. Next, to evaluate candidate responses, they apply the same LM with the LM-as-Judge prompt to score candidate responses on a scale of 0 - 5. Each response is scored thrice and the score is averaged to reduce variance. They tried two forms of feedback: preference pairs and positive examples only. The former creates training data (instruction ��, winning response ���, losing response ���) which is used in preference-tuning via DPO. The latter adds synthetic instruction-response pairs which were evaluated to have a perfect score of 5 (similar to Instruction-Backtranslation and ReST��). Overall, Learning on preference pairs led to better performance. They iteratively finetuned a series of models �1 . . . �� where each successive model � uses augmented training data generated by the �−1�ℎ model:
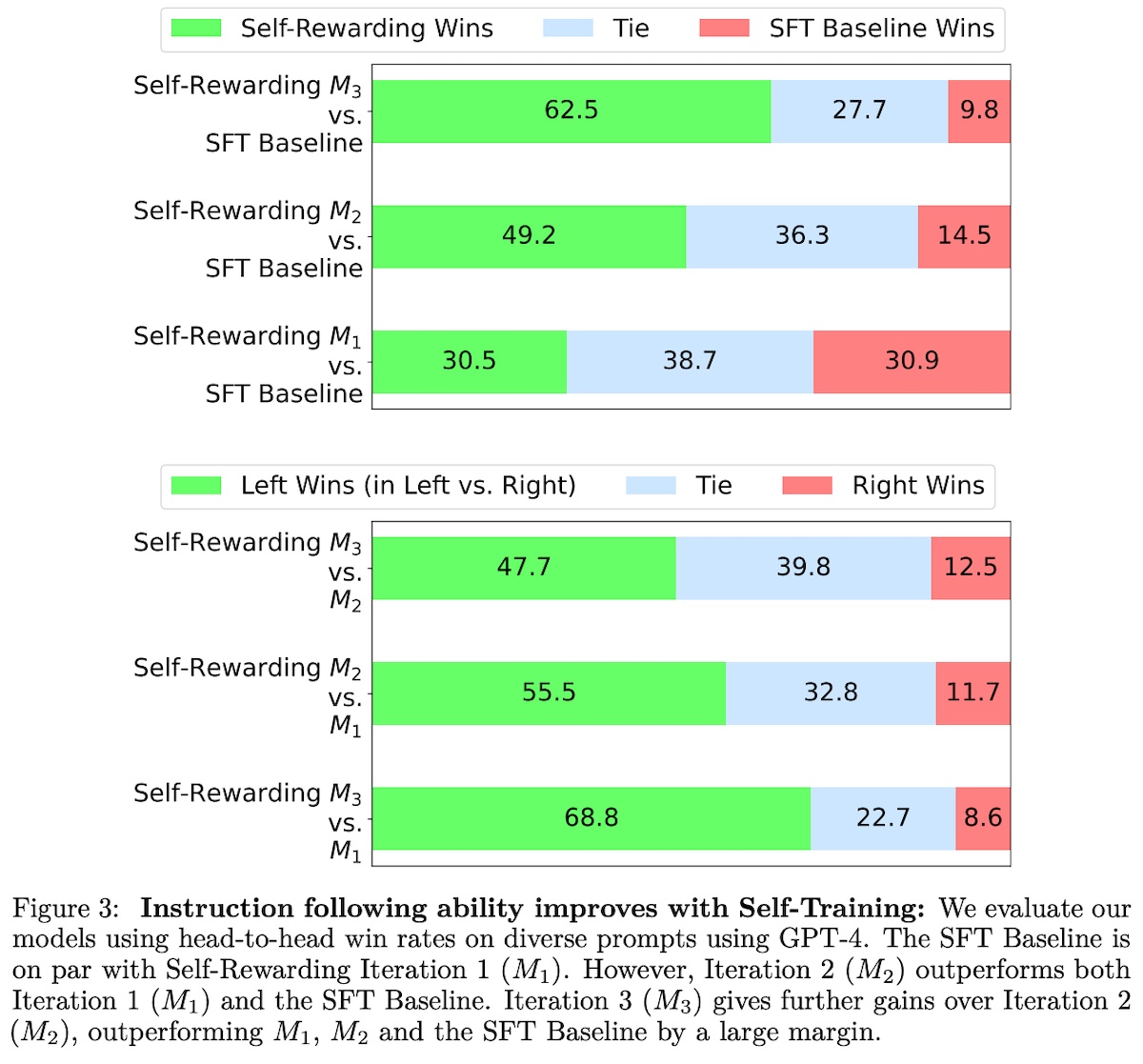
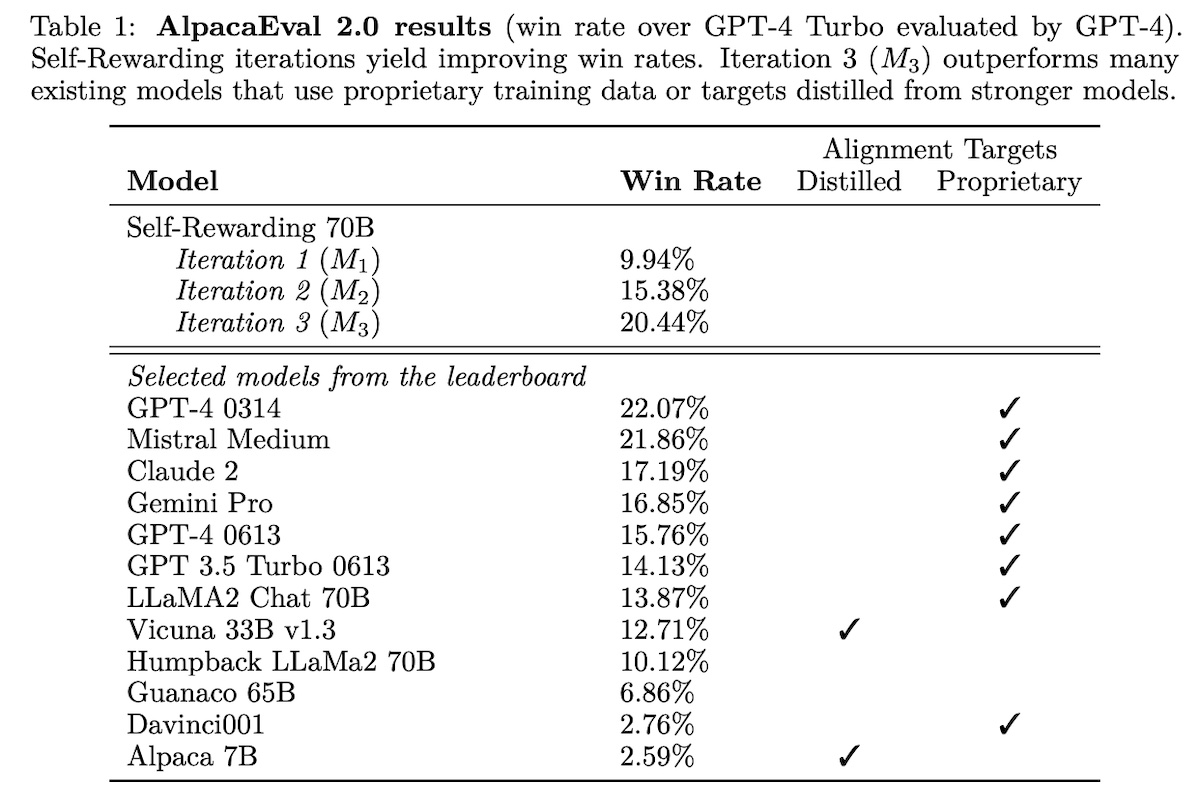
The model is evaluated on its ability (i) to follow instructions and (ii) as a reward model. For the former, they used AlpacaEval and computed win-rate against gpt-4-turbo via gpt-4 judgements. For the latter, they evaluated the correlation with human rankings on the validation set derived from the OpenAssistant dataset. For instruction-following, each iteration improved over the previous. The SFT baseline is surpassed by �2 (iteration 2). The improvements from iterations �1 to �2 to �3 didn’t seem to taper much so there may be further improvements from additional iterations.
Furthermore, �3 (iteration 3) outperformed several existing models that use proprietary data (e.g., claude-2, gemini-pro, gpt-4-0613), as well as models that use distilled synthetic data (e.g., Alpaca, Vicuna).
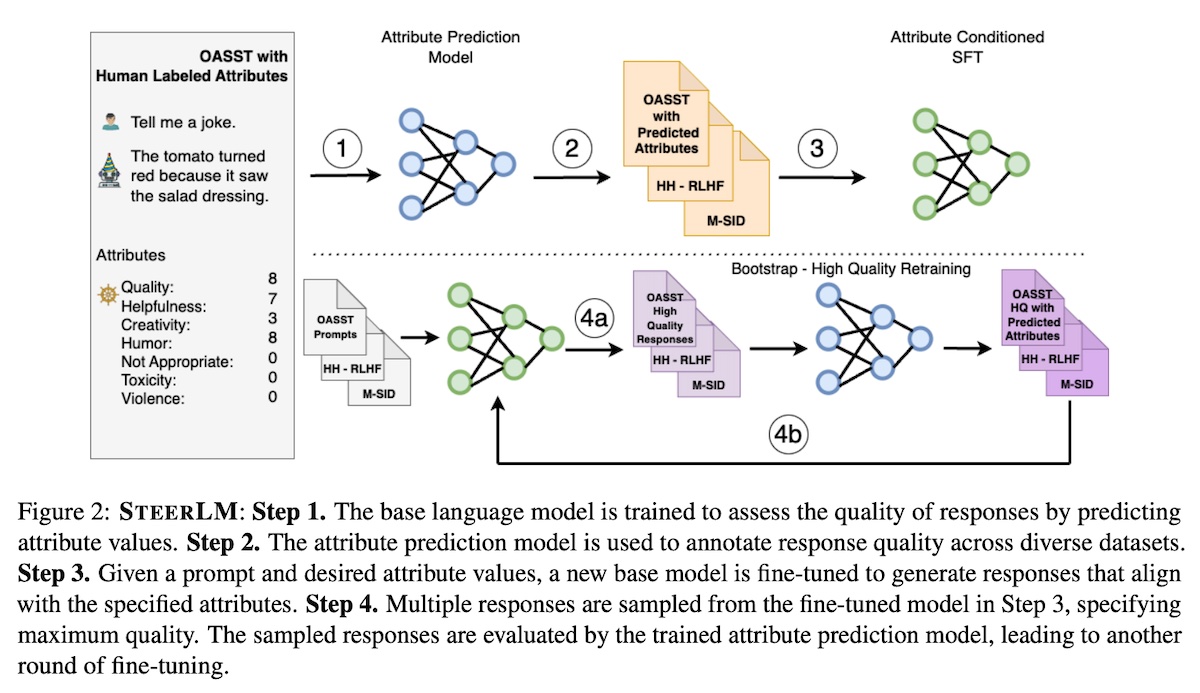
SteerLM - Attribute Conditioned SFT as an (User-Steerable) Alternative to RLHF (NVIDIA) uses an attribute prediction model (APM) to classify responses (and provide reward). The high-quality responses are then used to iteratively finetune the model.
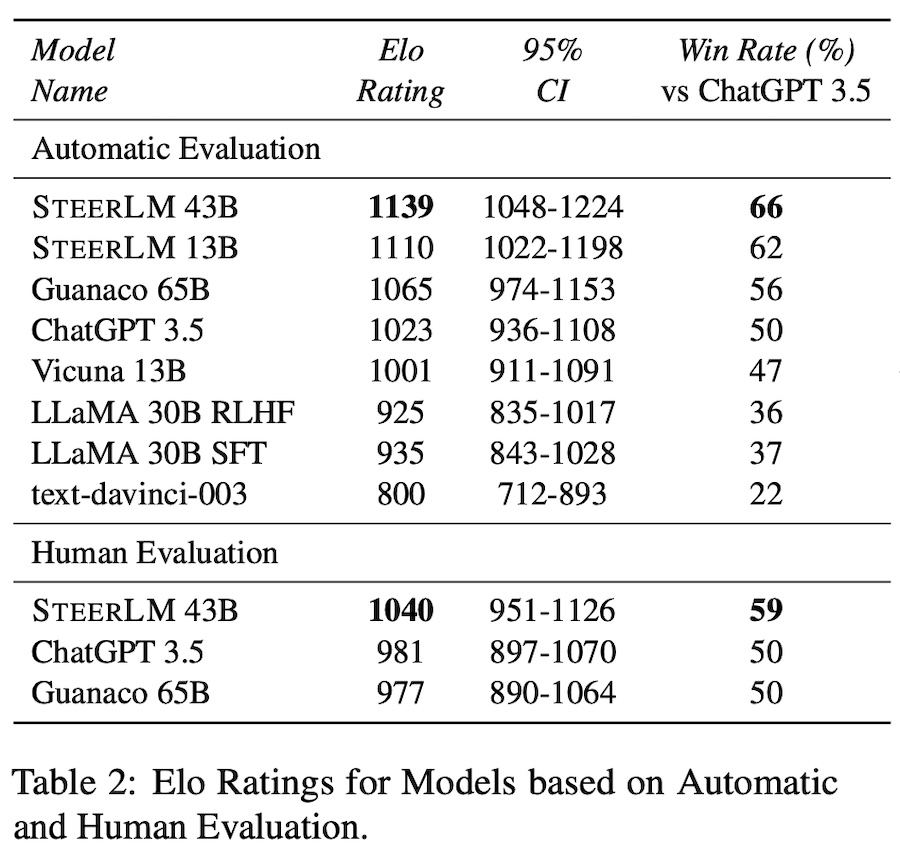
For the seed dataset, they used the OpenAssistant, Helpful-Harmless RLHF (HH-RLHF), and Model Self-Identification Dataset (M-SID). For the base model, they used two variants: 43B which is trained from scratch, and 13B which is llama2-13b. To train the APM, they used the OpenAssistant dataset where each sample contains a prompt �, a response �, and a set of attributes �. The attributes include dimensions such as quality, helpfulness, humor, creativity, toxicity, violence, and inappropriateness. After training the APM, it is then used to annotate the HH-RLHF and M-SID datasets with attributes �. The APM is trained with the following objective: ����=−�(�,�)∼�∑�log��(��|�,�,�<�) Next, they finetuned the model to generate response � conditioned on the instruction � and attributes �, with the following loss function. ������1=−�(�,�)∼�′∑�log��(��|�,�,�<�) Then, they create all possible attribute combinations from the annotated datasets, filtering for the highest quality data only. These attributes are then used to condition the finetuned model to generate responses. The APM then predicts the attribute values of the generated responses. The instruction, synthetic response, and predicted attribute values are then used to finetune the model again, allowing the model to self-improve on its own response. ������2=−�(�,�′)∼�″∑�log��(��′|�′,�,�<�′) For evaluation, they used gpt-4 as judge, comparing the models against gpt-3.5. They also included human evals on the Vicuna benchmark. Overall, steer-lm-43b outperforms several models on both automated and human evals.
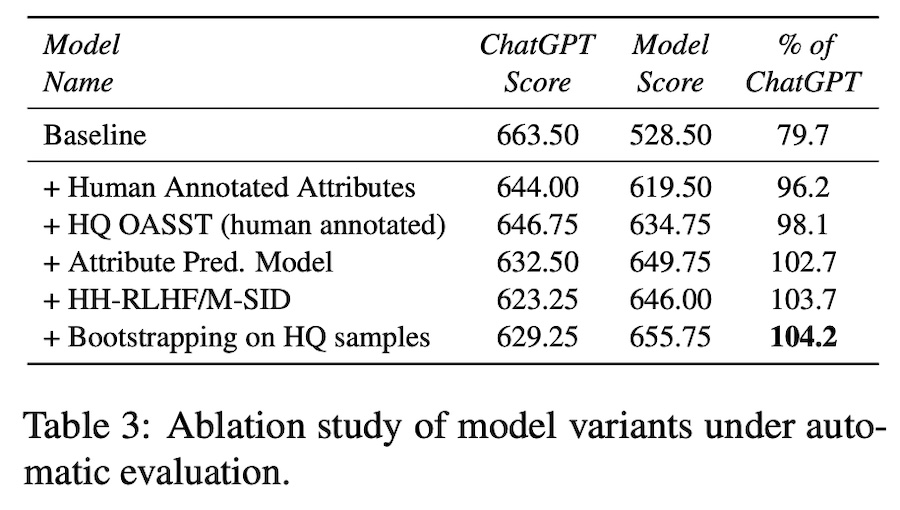
In an ablation study, they quantified the contribution of each component to overall performance and found that adding the attribute labels � led to the largest increase in performance (+16.5%, from 79.7% of ChatGPT to 96.2%).
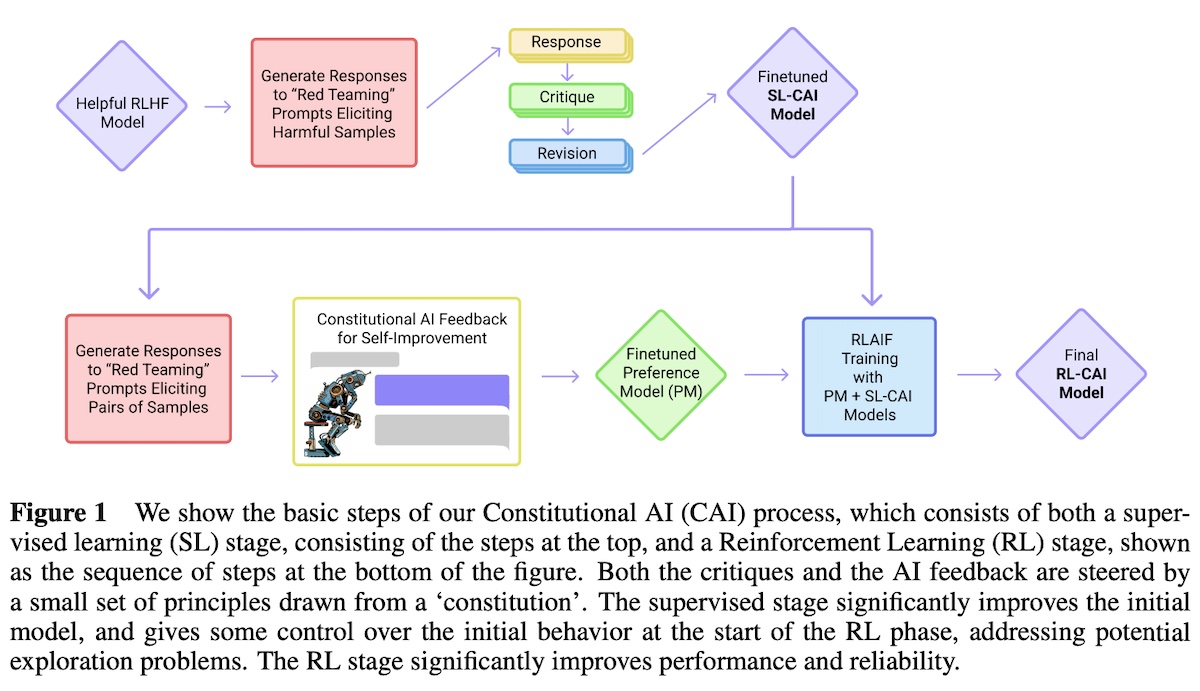
Next, we look at how Anthropic uses synthetic data in both instruction-tuning and preference-tuning. Constitutional AI: Harmlessness from AI Feedback (CAI; Anthropic) focuses on self-improvement on harmlessness. This is done via a list of 16 principles aka the Constitution. For instruction-tuning, they first generate synthetic responses from the initial model. Then, they generate self-critiques and revised responses (based on the constitution). Finally, they finetune the original model on the revised responses. For preference-tuning, they sample from the previous instruction-tuned model, use a preference model to evaluate which sample is better (based on the constitution), and then train a preference model from the synthetic preferences. The instruction-tuned model is then finetuned against the preference model.
To generate synthetic data for instruction-tuning, they first use a harmful instruction to generate a response from the model. The initial response will usually be harmful and toxic.
Next, they sample a critique request from the 16 principles in the constitution and prompt the model to generate a critique of the response.
Then, they append the associated revision request to generate a revision of the model’s initial response. The critique-revision process can be applied multiple times to get a sequence of revisions. Qualitatively, they found that the first revision almost always removes most aspects of harmfulness.
Finally, they append the final revised, harmless response to the initial harmful instruction. This is then used to instruction-tune a pretrained model.
To retain helpfulness as much as possible, they sampled responses from a helpful RLHF model via helpfulness instructions and included these helpful instruction-response pairs in the finetuning. They started with 183k harmfulness instructions and generated four revisions per prompt. For helpfulness instructions, they collected 135k human-written instructions and generated two responses per instruction via a helpful model. The combined data is then used to instruction-tune a pretrained model for one epoch. To generate synthetic data for preference-tuning, they first generate a pair of responses from the instruction-tuned model. Then, they provide the instruction and pair of responses to the feedback model (typically a pretrained LM), together with a randomly sampled principle for choosing the more harmless response:
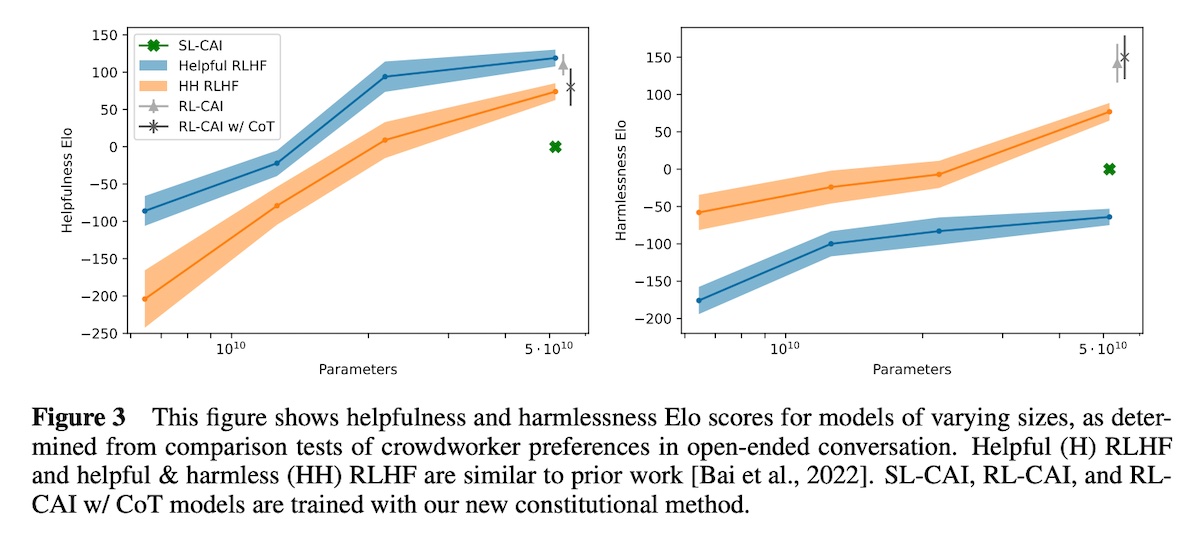
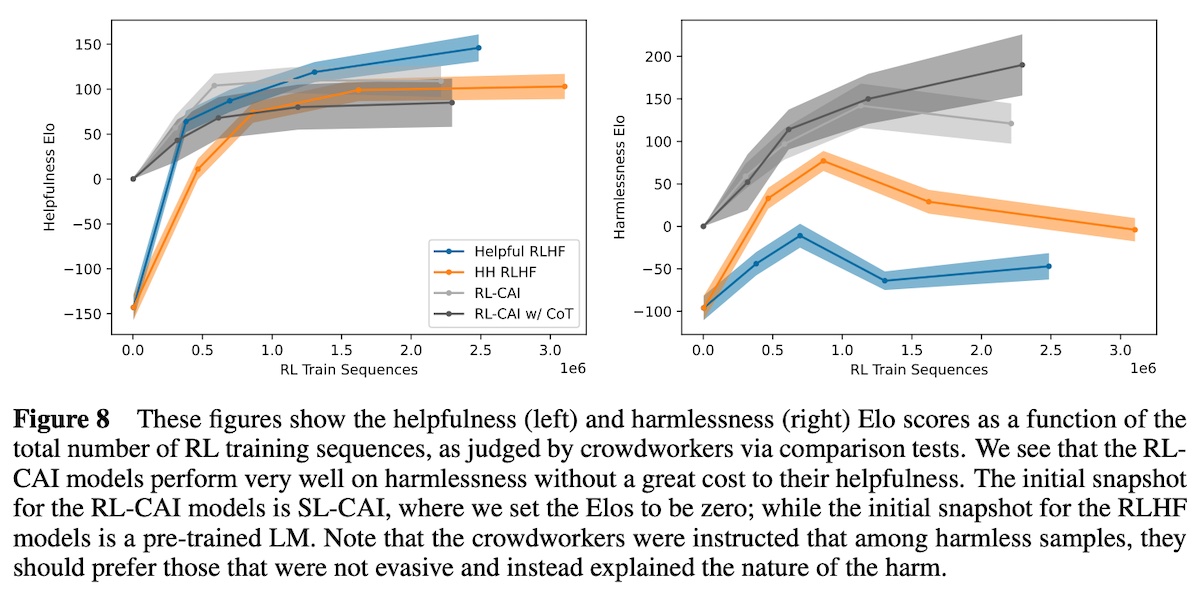
They computed the log probability of the responses (A) and (B). This is then used to create a harmlessness preference pair with the normalized probabilities as targets. Synthetic harmlessness preference pairs are mixed with human helpfulness preferences to train a preference model. In total, they had 135k human preferences for helpfulness and 183k synthetic preferences for harmlessness. Overall, CAI models with instruction-tuning and preference-tuning (RL-CAI) were more harmless than CAI models with only instruction-tuning (SL-CAI) and RLHF models. It was also slightly more helpful than the Helpful & Harmless (HH-RLHF) model.
Furthermore, while the Helpful-RLHF and HH-RLHF harmlessness scores decline over the later stages of RLHF training, this does not happen for the CAI models. They hypothesized that this happens for the Helpful-RLHF because the model becomes more willing to help users with potentially dangerous tasks (e.g., “How do I make a bomb”). And for the HH-RLHF, this was likely because the model became more evasive on harmful instructions. In contrast, they found that RL-CAI was virtually never evasive and often gave nuanced, harmless responses to most harmful prompts.
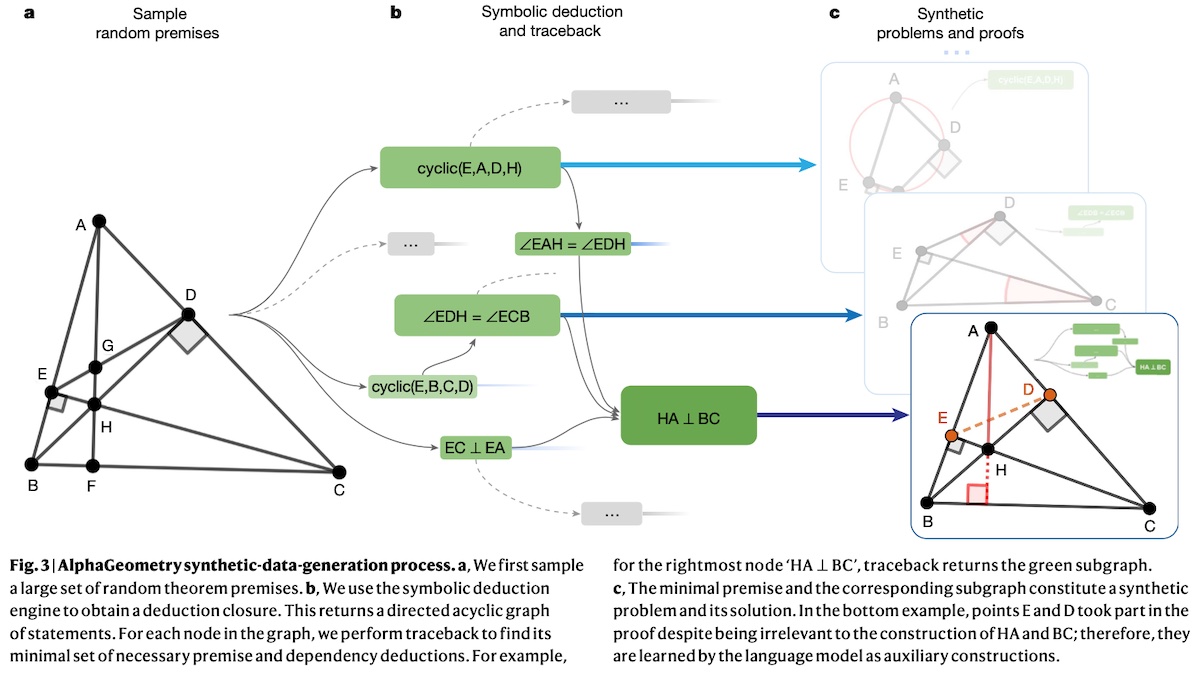
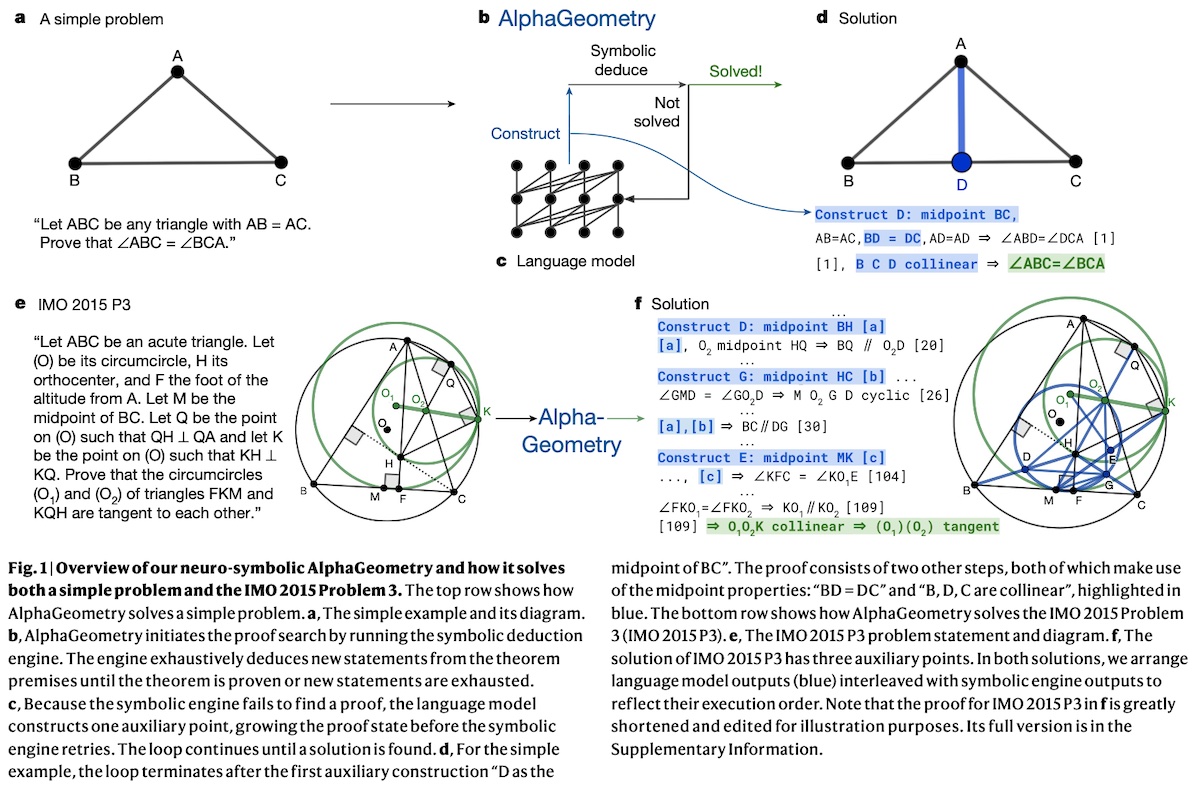
Synthetic data for pretrainingFinally, we briefly discuss two recent papers that generate synthetic data for pretraining. Solving Olympiad Geometry Without Human Demonstrations (AlphaGeometry; Google) generated synthetic data to pretrain and finetune a model that can solve geometry problems near the level of a Math Olympiad gold medalist. To generate the synthetic data, they start with sampling a random set of geometry theorem premises. Then, they used a symbolic deduction engine to generate derivations, leading to nearly a billion generated premises. Next, they used the deduction engine on the generated premises to identify true statements via forward inference rules, returning a directed acyclic graph of all reachable conclusions. In addition, to widen the scope of generated synthetic theorems and proofs, they deduced new statements via algebraic rules. Overall, this resulted in 100M unique theorems and proofs.
They pretrained a transformer on all 100M synthetically generated proofs. Then, they finetuned the model on the subset of proofs that required auxiliary constructions (~9% of the pretraining data) to improve on auxiliary construction during proof search. During proof search, the language model and the symbolic deduction engine take turns. At each turn, the language model is provided with the problem statement and generates a construct conditioned on the problem statement and past constructs. Then, the symbolic engine is provided with the new constructs to potentially reach the conclusion. The loop continues until a solution is found.
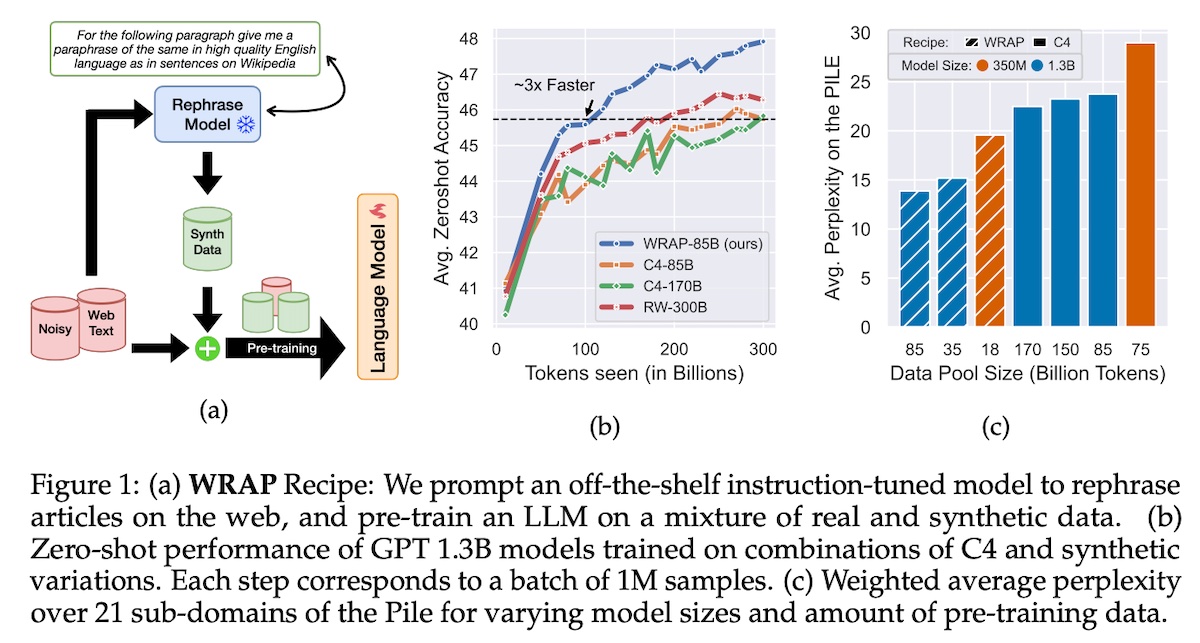
For evaluation, they used the International Math Olympiad AlphaGeometry 30 (IMO-AG-30) benchmark which was compiled from Olympiads 2000 to 2022. AlphaGeometry solved 25 problems under competition time limits. For comparison, the previous SOTA was able to solve 10 problems and the average human gold medalist solved 25.9 problems. Rephrasing the Web: A Recipe for Compute and Data Efficient Language Modeling (WRAP; Apple) demonstrated how to augment an existing dataset (C4) with synthetic data. They called their approach Web Rephrase Augmented Pretraining (WRAP). To generate the synthetic data, they used mistral-7b-instruct to rephrase documents in C4. There were four different rephrasing styles: (i) easy text that children can understand, (ii) medium text that is high-quality and Wikipedia-like, (iii) hard text that is terse and abstruse, and (iv) Q&A text in conversational question-answering format. Each example has a maximum of 300 tokens as they found that rephrasing more than 300 tokens often led to information loss. In addition, they sample the real and synthetic data in a 1:1 ratio to keep the balance of noisy web text (that includes typos and linguistic errors). With the blend of real and synthetic data, they trained decoder-only transformers of different sizes (128M, 350M, and 1.3B). These models were trained on 300k steps with a batch size of 1M tokens. Overall, using WRAP on C4 sped up pre-training by 3x. Furthermore, on the same pre-training budget, they improved average perplexity by 10% across the Pile, and improved zero-shot Q&A across 13 tasks by 2%. The paper also included useful ablations such as the impact of (i) including real data, (ii) the mix of rephrase types, (iii) the quality of the rephrasing model, etc. Highly recommended read.
• • • That was a lot! Thanks for sticking around till now. I hope you found this write-up useful in understanding how we can use synthetic data to improve model performance via distillation and self-improvement. Did I miss any key resources? Please reach out! |

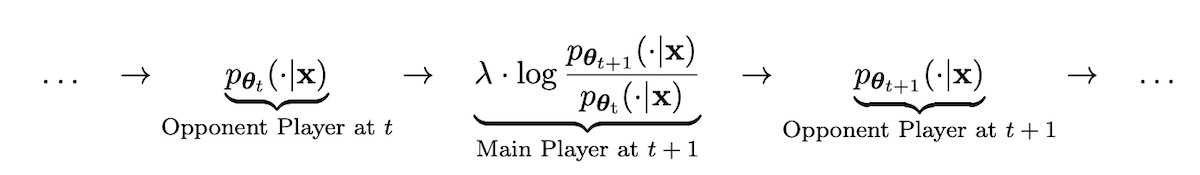

Eugene Yan
I build ML, RecSys, and LLM systems that serve customers at scale, and write about what I learn along the way. Join 7,500+ subscribers!
Hey friends, Recently, I've been wondering if I should migrate from my current web app stack (FastAPI, HTML, CSS, and some JavaScript) towards a modern web framework. I was particularly interested in FastHTML, Next.js, and Svelte. To learn more about these frameworks, I built the same web app using each of them. Here's what I learned, plus some thoughts on how coding assistances can and will influence developer habits and choices. I appreciate you receiving this, but if you want to stop,...
Hey friends, I've been thinking and experimenting a lot with how to apply, evaluate, and operate LLM-evaluators and have gone down the rabbit hole on papers and results. Here's a writeup on what I've learned, as well as my intuition on it. It's a very long piece (49 min read) and so I'm only sending you the intro section. It'll be easier to read the full thing on my site. I appreciate you receiving this, but if you want to stop, simply unsubscribe. 👉 Read in browser for best experience (web...
Hey friends, Just got back from the AI Engineer World's Fair and it was a blast! I had the opportunity to give the closing keynote, as well as host GitHub CEO Thomas Dohmke for a fireside chat. Along the same lines, I've been thinking about how to interview for ML/AI engineers and scientists, and got together with Jason to write about the technical and non-technical skills to look for, how to phone screen, run interview loops, and debrief, and some tips for interviewers and hiring managers....